
论文一时爽,复现火葬场
身如钢铁,心若琉璃
前言
随着技术门槛的降低以及在如今机器学习、深度学习变得日渐大白菜的大背景下。人人都能够上手训练神经网络调试参数,私以为没有数学基础已经相应的编程功底很难再实现自己的无可替代性,故开一贴,记录思考,寻求变革!
实现步骤
- 环境准备:
- 硬件篇:性能拉满,模型吃灰,不如去打游戏!
- 软件篇:总有de不完的BUG
- 分析模型
- 数学原理:谁会啊~你会嘛,我不会
- 模型实现:Ctrl+C+V:这我熟悉
- 模型实现
- 处理数据:PyTorch加载自己的数据集
- 模型搭建:???
- 模型训练:???
- 模型测试:???
环境准备
硬件设备:RTX30601、TITAN Xp2
软件:RTX3060:Nvidia462.30+CUDA11.1+cudnn8.0.1+pytorch1.8
TITAN Xp:Nvidia460.72+CUDA10.7+cudnn7.0.1+pytorch1.7
2021年下半年显卡选购攻略
分析模型
识别手写数字,除了使用传统的贝叶斯概率模型,感知机或者支持向量机做分类意外,使用图像的方法越来越主流,尤其是再imageNet,已经超越了人类达到了惊人的99%!
数学原理
LeNet-5出自论文Gradient-Based Learning Applied to Document Recognition,是一种用于手写体字符识别的非常高效的卷积神经网络。
PS:数学上的卷积操作自行参考网络与信号系统教科书(PS:如果没有卷积操作对数值特征的名感性,也就没有后来的图像处理什么事情了)
激活函数操作,选用,以及意义
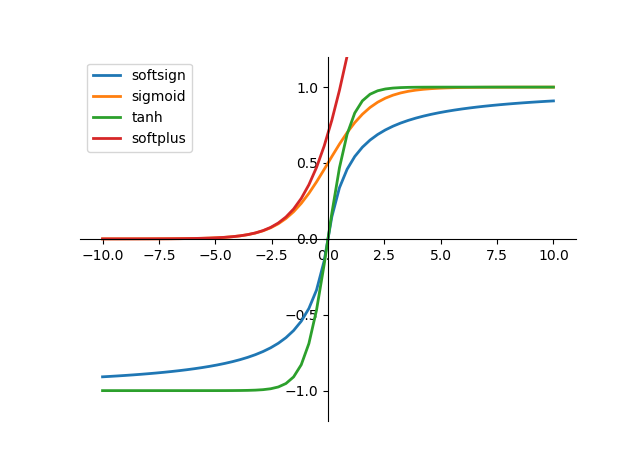
激活函数本质上是为了增强网络对非线性参数的拟合能力
激活函数是来向神经网络中引入非线性因素的,通过激活函数,神经网络就可以拟合各种曲线。如果不用激励函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
激活函数主要有两大类:Relu与sigmoid
sigmoid:sigmoid是使用范围最广的一类激活函数,具有指数的形状,它在物理意义上最为接近神经元。sigmoid的输出是(0,1),具有很好的性质,可以被表示做概率或者用于输入的归一化等等。
tanh: tanh也是一种非常常见的激活函数,与sigmoid相比,它的输出均值为0,这使得它的收敛速度要比sigmoid快,减少了迭代更新的次数。
Relu:ReLU是针对sigmoid和tanh的饱和性二提出的新的激活函数。从上图中可以很容易的看到,当x>0的时候,不存在饱和问题,所以ReLU能够在 x>0 的时候保持梯度不衰减,从而缓解梯度消失的问题。这让我们可以以有监督的方式训练深度神经网络,而无需依赖无监督的逐层训练。然而,随着训练的推进,部分输入会落入硬饱和区(即 x<0 的区域),导致权重无法更新,这种现象称为“神经元死亡”。
LeNet5参数详解(麻雀虽小,五脏俱全)
数据类型:有Mnist数据集图像为3232
1. 先把图像的特征卷积出来(卷积核过大过小都不好,过大容易丢失细节信息,过小容易过拟合以及降低模型训练速度,一般选用样本大小的五分之一较为适宜),这里采用55,故原特征降为(32-5+1)2828
2. 激活函数使用()
3. 池化过滤掉一些不重要的特征,消除弱化扰动,提高对特征识别的鲁棒性(池化操作还有很好的特征降维、防止过拟合的作用)采用22,故得1414
4. 继续重复卷积得1010(14-5+1),这里通过特征图的组合运算得到了16各特征图。第一次池化之后是第二次卷积,第二次卷积的输出是C3,16个10x10的特征图,卷积核大小是 55. 我们知道S2 有6个 14*14 的特征图,怎么从6 个特征图得到 16个特征图了? 这里是通过对S2 的特征图特殊组合计算得到的16个特征图。具体如下:

5.继续下采样池化
6.全连接后输出
模型实现
数据处理dataset.py
1 | |
模型搭建model.py
1 | |
模型训练train.py
1 | |
模型测试test.py
1 | |