
muti-machin deep learning
MMDL综述篇:三句话从入门到劝退
PS:在此之前,需要提到的是:无论是论文笔记,还是总结性的读物,都包含了作者自己的理解和二次加工,想要做出好的工作必定需要自己看论文和总结。这里推荐一套来自卡内基梅隆大学的网课
来个段子
由于近几年深度学习火热的原因,很多单一领域任务的模型性能难以提升,所以才有了混合模态灌水大法
知乎一文读懂
pytorch多模态实践基础
视觉问答VQA知识资料全集
音视频融合
常见的fusion
文献1:《Multimodal Machine Learning: A Survey and Taxonomy》
摘要
Abstract—Our experience of the world is multimodal - we see objects, hear sounds, feel texture, smell odors, and taste flavors.
Modality refers to the way in which something happens or is experienced and a research problem is characterized as multimodal when
it includes multiple such modalities. In order for Artificial Intelligence to make progress in understanding the world around us, it needs
to be able to interpret such multimodal signals together. Multimodal machine learning aims to build models that can process and relate
information from multiple modalities. It is a vibrant multi-disciplinary field of increasing importance and with extraordinary potential.
Instead of focusing on specific multimodal applications, this paper surveys the recent advances in multimodal machine learning itself
and presents them in a common taxonomy. We go beyond the typical early and late fusion categorization and identify broader
challenges that are faced by multimodal machine learning, namely: representation, translation, alignment, fusion, and co-learning. This
new taxonomy will enable researchers to better understand the state of the field and identify directions for futur
分析:综述太笼统,一下就不展开了
- 解决问题:是一篇行业大牛所写的综述,总结过去展望了未来,嗯,很好~
- 论文动机:多模态领域内容杂乱,坑数不胜数,江湖分久必合
- 研究方法:无情论文阅读法
- 其他内容:总结了多模态信息融合过程中的表示(联合/嵌入),映射,融合,协同等学习方法
研究内容和应用领域
- 五大类:表示:多模态表征,对齐:跨模态对齐,映射(翻译),融合(多模态融合),协同
- 如今的主要任务:
- 跨模态的预训练模型:Vision-Language Model
- 跨任务预训练
- Language-Audio
- ext-to-Speech Synthesis: 给定文本,生成一段对应的声音。
- Audio Captioning:给定一段语音,生成一句话总结并描述主要内容。(不是语音识别)
- Vision-Audio
- Audio-Visual Speech Recognition(视听语音识别):给定某人的视频及语音进行语音识别。
- Video Sound Separation(视频声源分离):给定视频和声音信号(包含多个声源),进行声源定位与分离。
- Image Generation from Audio: 给定声音,生成与其相关的图像。
- Speech-conditioned Face generation:给定一段话,生成说话人的视频。
- Audio-Driven 3D Facial Animation:给定一段话与3D人脸模版,生成说话的人脸3D动画。
- Vision-Language
- Image/Video-Text Retrieval (图(视频)文检索): 图像/视频<–>文本的相互检索。
- Image/Video Captioning(图像/视频描述):给定一个图像/视频,生成文本描述其主要内容。
- Visual Question Answering(视觉问答):给定一个图像/视频与一个问题,预测答案。
- Image/Video Generation from Text:给定文本,生成相应的图像或视频。
- Multimodal Machine Translation:给定一种语言的文本与该文本对应的图像,翻译为另外一种语言。
- Vision-and-Language Navigation(视觉-语言导航): 给定自然语言进行指导,使得智能体根据视觉传感器导航到特定的目标。
- Multimodal Dialog(多模态对话): 给定图像,历史对话,以及与图像相关的问题,预测该问题的回答。
- 定位相关的任务
- Visual Grounding:给定一个图像与一段文本,定位到文本所描述的物体。
- Temporal Language Localization: 给定一个视频即一段文本,定位到文本所描述的动作(预测起止时间)。
- Video Summarization from text query:给定一段话(query)与一个视频,根据这段话的内容进行视频摘要,预测视频关键帧(或关键片段)组合为一个短的摘要视频。
- Video Segmentation from Natural Language Query: 给定一段话(query)与一个视频,分割得到query所指示的物体。
- ideo-Language Inference: 给定视频(包括视频的一些字幕信息),还有一段文本假设(hypothesis),判断二者是否存在语义蕴含(二分类),即判断视频内容是否包含这段文本的语义。
- Object Tracking from Natural Language Query: 给定一段视频和一些文本,进行
- Language-guided Image/Video Editing: 一句话自动修图。给定一段指令(文本),自动进行图像/视频的编辑。
- 更多模态
- Affect Computing (情感计算):使用语音、视觉(人脸表情)、文本信息、心电、脑电等模态进行情感识别。
- Medical Image:不同医疗图像模态如CT、MRI、PET
- RGB-D模态:RGB图与深度图
文献2:《ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision》
分析
注:这是2021最轻量级的多模态融合模型(目前计算资源下仅有能跑得动的多模态模型)
摘要
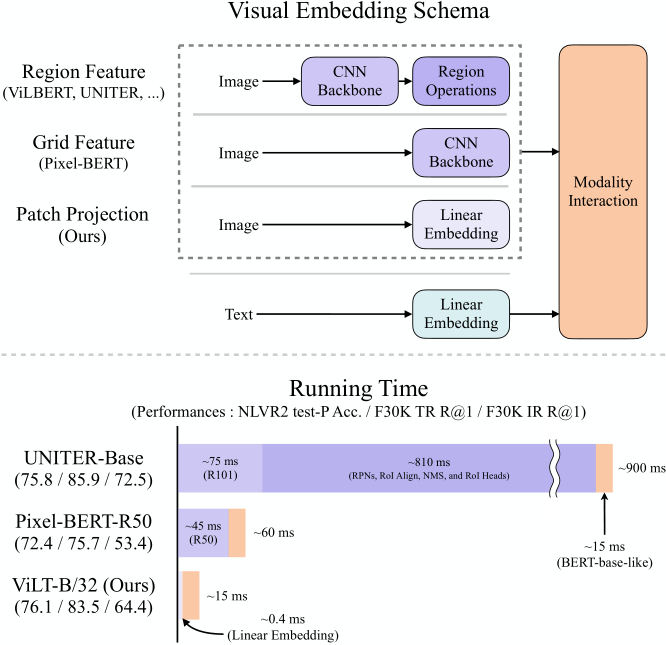
Introduction
- 当今多模态领域(2019年以后),VLP(vision-and-language pre—training)模型已经成为了主流,面对大型网络的应用都是pre-traing+final tune的模式。
- 一开始的VLP在视觉端都是采用的深度卷积神经网络实现(CNN),是以区域特征为主要的视觉语言密集型嵌入方法。Bert的提出是这个趋势的一种例外,他是Resnet的一种变体,取代了cnn/目标检测模块。
- 很多VLP都是聚焦于提高如果提高视觉嵌入器cnn的性能,但缺点也很明显,在真实的应用中,对目标提取特征并训练是一个缓慢的过程。
- 所以作者打算减轻视觉输入的嵌入,使其变成快速的轻量级输入,2020年的一项 (Dosovitskiy et al.,2020; Touvron et al., 2020) 工作说明不用区域特征提取而是进行图形投影就已经可以有效地嵌入像素(让模型学习到像素地语义)
- 文章提出Vilt 一个可以同时处理视觉语言特质的轻量级预训练网络(如下图),作者有三点贡献:
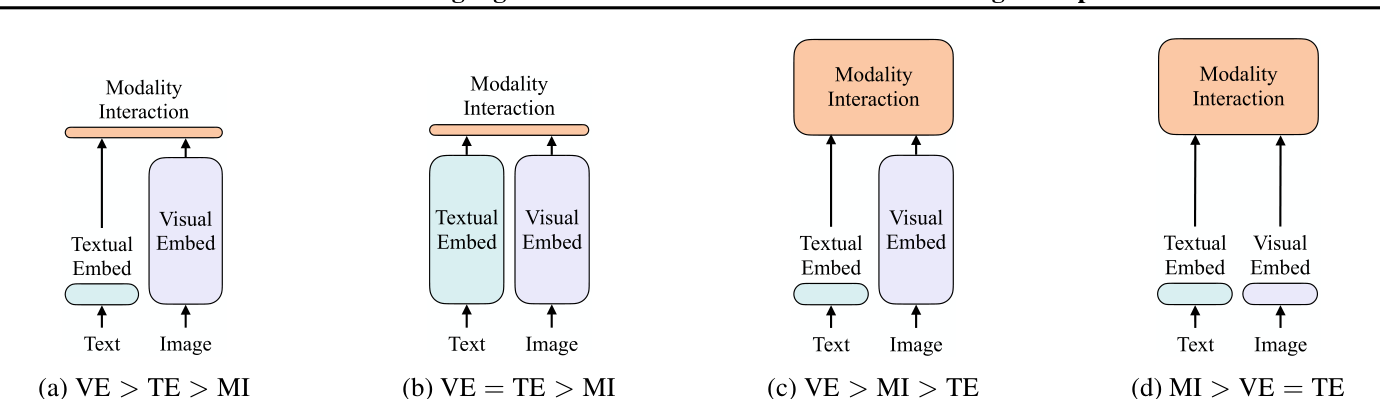
基于参数和计算的模型表达水平是否一致
是否有在深层网络进行交互
如下图:![four ways compare]()
PS:(1)是2017年提出的VSE (2)是2021年的CLIP (3)是2018年perez的多模态模型 (4)是作者transformer是如今VLP主流的信息转换器,为了不引入额外的参数,作者选择了单流作为交互模式,单流就是视觉和语义信息同时通过一个embedding。
架构上,引入片面投影而不是区域网格特征。
目标检测不可能比程序主干或者单层卷积要快,冻结视觉模块主要是为了减小训练时间而不是为了进行推理预测。更不说其有可能影响性能。
VilT model/mudle
![model structuer]()
(待进行代码研究)
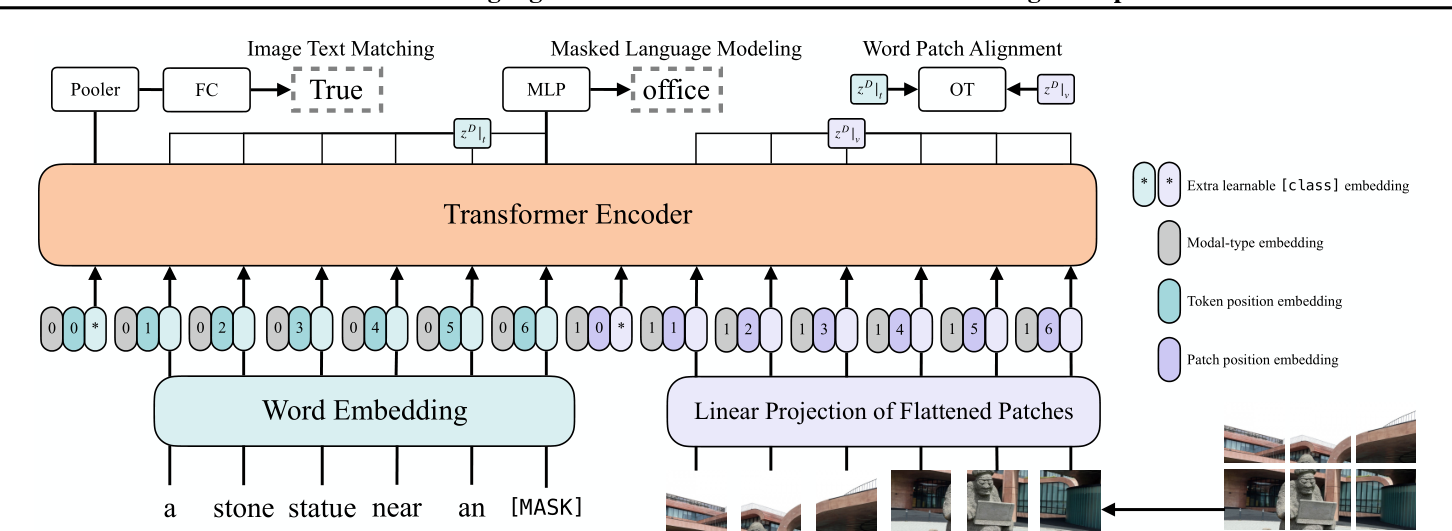
实现计算原理:
$$
\begin{aligned}
\bar{t} &=\left[t_{\text {class }} ; t_{1} T ; \cdots ; t_{L} T\right]+T^{\text {pos }} & & \
\bar{v} &=\left[v_{\text {class }} ; v_{1} V ; \cdots ; v_{N} V\right]+V^{\text {pos }} & & \
z^{0} &=\left[\bar{t}+t^{\text {type }} ; \bar{v}+v^{\text {type }}\right] & & \
\hat{z}^{d} &=\operatorname{MSA}\left(\operatorname{LN}\left(z^{d-1}\right)\right)+z^{d-1}, & & d=1 \ldots D \
z^{d} &=\operatorname{MLP}\left(\operatorname{LN}\left(\hat{z}^{d}\right)\right)+\hat{z}^{d}, & & d=1 \ldots D \
p &=\tanh \left(z_{0}^{D} W_{\text {pool }}\right) & &
\end{aligned}
$$
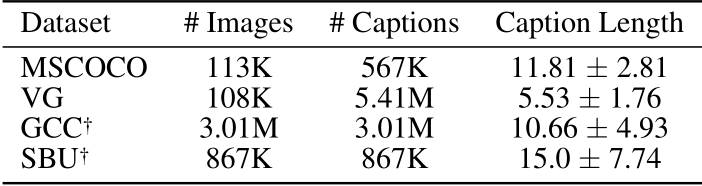
experiments
- 采用了四个数据集:MSCOCO\VG\GCC\SBU
![使用的数据集table 1]()
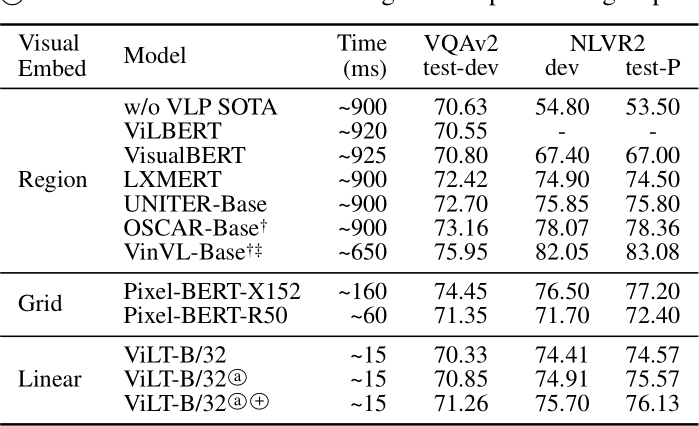
- VQA和NLVR任务下的性能表现:
![模型对比]()
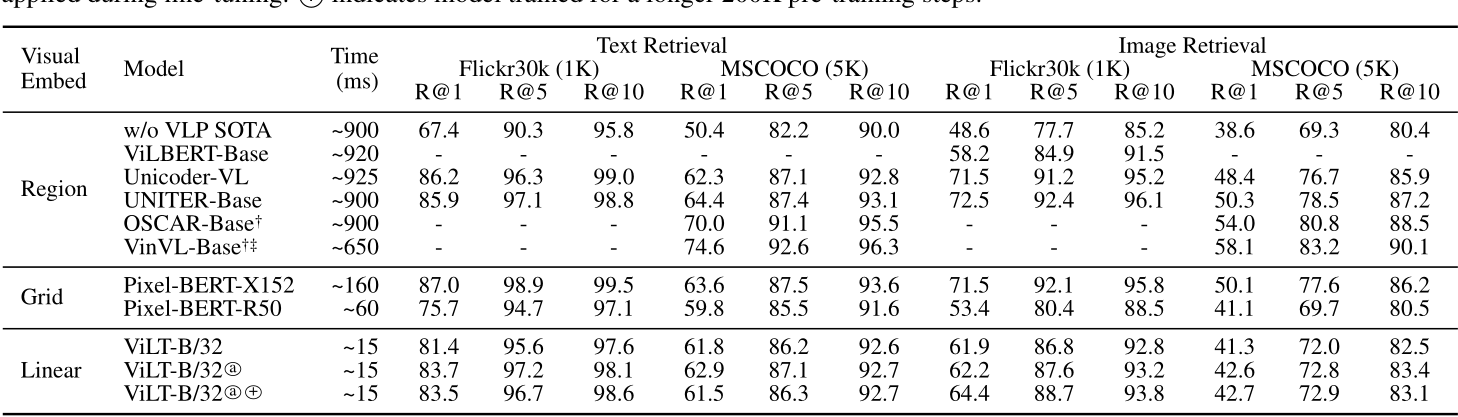
- Text Retrieval and Image Retrieval
- Zero shot(零样本学习)
![table]()
- nomal
![table]()
- Zero shot(零样本学习)
- Ablation Study
Conclusion and Future work

- present a mionimal VLP architecture Vilt
- Vilt is competent competitors
- future work on VLP
some idea as this page
- 多模态融合基本都要走transformer (当然,也可以不走,但要研究新的信息学习范式出来)
- 借鉴人认识新事物的多模态辅助场景,很多时候,模态都起到可以互为数据集增补信息,或者堆叠出新理解质变,也就是说,反正都是收集各种语义,训练出语言背后的意义。
- 大多数场景下,多模态并不能让我们更本质的感受到信息,只能深化感受提高用户体验。
文献3:《多模态预训练综述》
分析
Vision-Language 预训练模型
寻找预训练模型
VCR榜单
除此之外,一些之前的有关预训练模型的其他方向的trick也被同步应用到了多模态预训练模型,比如Prompt-Tuning等等:
https://arxiv.org/pdf/2109.01229.pdf
https://arxiv.org/pdf/2109.11797.pdf
需要说明的是目前这一赛道大的方面分为两块:通用型的预训练&特定领域的预训练,具体一些论文大家可以看:
地址
预训练模型最新进展特征提取
- 特征提取要解决的问题是怎么分别量化文字和图像,进而送到模型学习?
- 特征融合要解决的问题是怎么让文字和图像的表征交互?
- 预训练任务就是怎么去设计一些预训练任务来辅助模型学习到图文的对齐信息?
目前这三个技术的通常做法是:
(1) 特征提取:文本端的表征标配就是bert的tokenizer,更早的可能有LSTM;图像的话就是使用一些传统经典的卷积网络,按提取的形式主要有三种Rol、Pixel、Patch三种形式。
(2) 特征融合:目前的主流的做法不外乎两种即双流two-stream或者单流single-stream;前者基本上就是双塔网络,然后在模型最后的时候设计一些layer进行交互,所以双流结构的交互发生的时间更晚。后者就是一个网络比如transformer,其从一开始就进入一个网络进行交互,所以单流结构的交互时间发生的更早且全程发生,更灵活;当然还有一类是Multi-stream(MMFT-BERT),目前还不多,不排除将来出现基于图文音等Multi-stream多模态模型。
(3) 预训练任务:这里就是最有意思的地方,也是大部分多模态paper的idea体现。这里就先总结一些常见的标配任务,一些特色的任务后面paper单独介绍。