问题话python编程
初见python便觉得:漂亮!
前言
我是从大二开始接触python编程的,当时玩的树莓派linux系统,所以很自然地开始使用起自带的python,说来也奇怪,当时的我在原生的python编辑器还有Vim模式下编辑得不亦乐乎(当然刚开始时非常痛苦)
由于需求紧迫,只能现学现用,从硬件IO调用开始,学习python的基础语法,资源管理,包的导入和调用,类与实例,元组与字典等等,python给我的感官就是很精简,还可以边运行边输出(解释型语言,不需要像C一样经过编译器编译和底层连接)可以说十分亲民!
但是我的打怪路线注定了我是需要什么学的什么,零零散散的(现在在回顾自己之前上传到GitHub上的代码真的不忍直视),久不用就会忘记许多的操作。故作此篇,理一理我的python编程技术和自己对python的理解。
变量类型(学会对变量或者数据结构进行各种操作)
python的变量类型有哪几种,区别是什么?
以下四种
列表(list):有序可修改,可以通过索引查找,比较,切片
- 列表是python中很常见的序列结构,但因为其本身是可变的,有时候又不太可靠,对链表主要有增加、插入、删除等操作
- 增加:直接+号拼接两个列表、append()往列表后添加、extend()逐个追加元素
- 插入:insert(索引,数据)、list[起点:终点]=数据
- 删除:del list[索引]、list.pop(索引)、list.remove(元素):删去首个对应元素、list.clear
- 基本操作符:len(list)、[] + []、 [‘hi’]*4 = [‘hi’,‘hi’,‘hi’,‘hi’] 、3 in [list]:True of false、for x in []:print(x)
- 截取:list[:]:得到的还是一个列表
- 统计元素:list.count(obj)统计某个元素在列表中出现的次数
- 将列表反向: list.reverse()
- 列表排序:list.sort(cmp=None, key=None, reverse=False)
- end
元组(tuple):有序不可修改,可索引,切片
- Python 的元组与列表类似,不同之处在于元组的元素不能修改。用小括号表示,创建如下元组不可以修改,但是可以通过加号连接,也可以向字典或者列表转化
1
2
3tup1 = ('physics', 'chemistry', 1997, 2000)
tup2 = (1, 2, 3, 4, 5 )
tup3 = "a", "b", "c", "d"
字典(dict): 使用键值对关联数据,无循序,通过key查找
字典是python中常用的一种数据结构,用来存放具有映射关系的数据(key,value)
- 注:
- 字典里的key是关键数据,而且程序需要通过key来访问value,因此字典中的key不允许重复。
- 可以用花括号创建字典,也可以用dict()来创建字典
- 在使用花括号语法创建字典时,花括号中应包含多个 key-value 对,key 与 value 之间用英文冒号隔开;多个 key-value 对之间用英文逗号隔开。
- 内置函数:
- cmp(或者operator.eq)
- len(dict)数里面所有的键的个数
- str(dict)输出成字符串打印
- type()
- 内置方法:
- dict.clear()
- dict.copy()
- dict.fromkeys(seq[.val])
- dict.get(key,default)#返回指定key的val值,如果没有,则返回default
- dict.has_key(key)有返回True,没有返回false
- dict.items()转化成可遍历的元组,列表形式
- dict.keys()以列表拿到dict中所有的key
- dict.values()以列表拿到dict中所有的value
- dict.update(dict2)把字典2的键值对更新到1里
- pop(key[,default])删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。
- popitem()返回并删除字典中的最后一对键和值
- end
集合(set):无序可修改,无重复无索引,自动去重
遍历方法
1 | |
数据类型
| 字符串 | 数字 | 列表 | 元组 | 字典 | 集合 |
类的使用
- 类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- 类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
- 数据成员:类变量或者实例变量, 用于处理类及其实例对象的相关的数据。
- 方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的 重写。
- 局部变量:定义在方法中的变量,只作用于当前实例的类。
- 实例变量:在类的声明中,属性是用变量来表示的。这种变量就称为实例变量,是在类声明的内部但是在类的其他成员方法之外声明的。
- 继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟”是一个(is-a)”关系(例图,Dog是一个Animal)。
- 实例化:创建一个类的实例,类的具体对象。
- 方法:类中定义的函数。
- 对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
函数使用
- Python return和yield的区别,以及print和return的作用
- 相同点:都是返回函数的执行结果
- 不同点:return是一次返回函数的结果。返回后继续执行。yield是让函数变成一个生成器,生成器每次产生一个值(yield语句),函数被冻结,唤醒后再产生一个值
- yield生成器相比return一次返回所有结果的优势
- 反应快
- 省空间
- 更灵活调整调用返回值
- print和return
- print是输出结果到控制端或者说终端
- return是返回一个值
- 参数顺序:必选参数,默认参数,可变参数,命名关键字参数,关键字参数
可变参数必须在关键字参数之前
内置模块/函数
Python中collections模块:这个模块实现了特定目标的容器,以提供Python标准内建容器 dict、list、set、tuple 的替代选择。
- Counter:字典的子类,提供了可哈希对象的计数功能
- defaultdict:字典的子类,提供了一个工厂函数,为字典查询提供了默认值
- OrderedDict:字典的子类,保留了他们被添加的顺序
- namedtuple:创建命名元组子类的工厂函数
- deque:类似列表容器,实现了在两端快速添加(append)和弹出(pop)
- ChainMap:类似字典的容器类,将多个映射集合到一个视图里面
Counter:主要是用来对你访问的对象进行频率计数,
1
2
3
4
5
6>>> import collections
>>> collections.Counter('hello world')
Counter({'l': 3, 'o': 2, 'h': 1, 'e': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1})
# 统计单词数
>>> collections.Counter('hello world hello world hello nihao'.split())
Counter({'hello': 3, 'world': 2, 'nihao': 1})常用方法有:
- elements():返回一个迭代器,每个元素重复计算的个数,如果一个元素的计数小于1,就会被忽略。
- most_common([n]):返回一个列表,提供n个访问频率最高的元素和计数
- subtract([iterable-or-mapping]):从迭代对象中减去元素,输入输出可以是0或者负数
- update([iterable-or-mapping]):从迭代对象计数元素或者从另一个 映射对象 (或计数器) 添加。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26>>> c = collections.Counter('hello world hello world hello nihao'.split())
>>> c
Counter({'hello': 3, 'world': 2, 'nihao': 1})
# 获取指定对象的访问次数,也可以使用get()方法
>>> c['hello']
3
>>> c = collections.Counter('hello world hello world hello nihao'.split())
# 查看元素
>>> list(c.elements())
['hello', 'hello', 'hello', 'world', 'world', 'nihao']
# 追加对象,或者使用c.update(d)
>>> c = collections.Counter('hello world hello world hello nihao'.split())
>>> d = collections.Counter('hello world'.split())
>>> c
Counter({'hello': 3, 'world': 2, 'nihao': 1})
>>> d
Counter({'hello': 1, 'world': 1})
>>> c + d
Counter({'hello': 4, 'world': 3, 'nihao': 1})
# 减少对象,或者使用c.subtract(d)
>>> c - d
Counter({'hello': 2, 'world': 1, 'nihao': 1})
# 清除
>>> c.clear()
>>> c
Counter()
defaultdict
collections.defaultdict(default_factory)为字典的没有的key提供一个默认的值。参数应该是一个函数,当没有参数调用时返回默认值。如果没有传递任何内容,则默认为None。1
2
3
4
5
6>>> d = collections.defaultdict()
>>> d
defaultdict(None, {})
>>> e = collections.defaultdict(str)
>>> e
defaultdict(<class 'str'>, {})defaultdict的一个典型用法是使用其中一种内置类型(如str、int、list或dict)作为默认工厂,因为这些内置类型在没有参数调用时返回空类型。
1
2
3
4
5
6
7
8
9
10
11
12
13>>> d = collections.defaultdict(str)
>>> d
defaultdict(<class 'str'>, {})
>>> d['hello']
''
>>> d
defaultdict(<class 'str'>, {'hello': ''})
# 普通字典调用不存在的键时,将会抛异常
>>> e = {}
>>> e['hello']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'hello'OrderedDict
Python字典中的键的顺序是任意的:它们不受添加的顺序的控制。
collections.OrderedDict类提供了保留他们添加顺序的字典对象。1
2
3
4
5
6
7>>> from collections import OrderedDict
>>> o = OrderedDict()
>>> o['key1'] = 'value1'
>>> o['key2'] = 'value2'
>>> o['key3'] = 'value3'
>>> o
OrderedDict([('key1', 'value1'), ('key2', 'value2'), ('key3', 'value3')])namedtuple
三种定义命名元组的方法:第一个参数是命名元组的构造器(如下的:Person,Human)1
2
3
4>>> from collections import namedtuple
>>> Person = namedtuple('Person', ['age', 'height', 'name'])
>>> Human = namedtuple('Human', 'age, height, name')
>>> Human2 = namedtuple('Human2', 'age height name')实例化命名元组
1
2
3
4
5
6
7
8
9
10>>> tom = Person(30,178,'Tom')
>>> jack = Human(20,179,'Jack')
>>> tom
Person(age=30, height=178, name='Tom')
>>> jack
Human(age=20, height=179, name='Jack')
>>> tom.age #直接通过 实例名+.+属性 来调用
30
>>> jack.name
'Jack'deque
collections.deque返回一个新的双向队列对象,从左到右初始化(用方法 append()) ,从 iterable (迭代对象) 数据创建。如果 iterable 没有指定,新队列为空。
collections.deque队列支持线程安全,对于从两端添加(append)或者弹出(pop),复杂度O(1)。虽然list对象也支持类似操作,但是这里优化了定长操作(pop(0)、insert(0,v))的开销。
如果 maxlen 没有指定或者是 None ,deques 可以增长到任意长度。否则,deque就限定到指定最大长度。一旦限定长度的deque满了,当新项加入时,同样数量的项就从另一端弹出。
支持的方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14append(x):添加x到右端
appendleft(x):添加x到左端
clear():清楚所有元素,长度变为0
copy():创建一份浅拷贝
count(x):计算队列中个数等于x的元素
extend(iterable):在队列右侧添加iterable中的元素
extendleft(iterable):在队列左侧添加iterable中的元素,注:在左侧添加时,iterable参数的顺序将会反过来添加
index(x[,start[,stop]]):返回第 x 个元素(从 start 开始计算,在 stop 之前)。返回第一个匹配,如果没找到的话,升起 ValueError 。
insert(i,x):在位置 i 插入 x 。注:如果插入会导致一个限长deque超出长度 maxlen 的话,就升起一个 IndexError 。
pop():移除最右侧的元素
popleft():移除最左侧的元素
remove(value):移去找到的第一个 value。没有抛出ValueError
reverse():将deque逆序排列。返回 None 。
maxlen:队列的最大长度,没有限定则为None。ChainMap
一个 ChainMap 将多个字典或者其他映射组合在一起,创建一个单独的可更新的视图。 如果没有 maps 被指定,就提供一个默认的空字典 。ChainMap是管理嵌套上下文和覆盖的有用工具。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23>>> from collections import ChainMap
>>> d1 = {'apple':1,'banana':2}
>>> d2 = {'orange':2,'apple':3,'pike':1}
>>> combined_d = ChainMap(d1,d2)
>>> reverse_combind_d = ChainMap(d2,d1)
>>> combined_d
ChainMap({'apple': 1, 'banana': 2}, {'orange': 2, 'apple': 3, 'pike': 1})
>>> reverse_combind_d
ChainMap({'orange': 2, 'apple': 3, 'pike': 1}, {'apple': 1, 'banana': 2})
>>> for k,v in combined_d.items():
... print(k,v)
...
pike 1
apple 1
banana 2
orange 2
>>> for k,v in reverse_combind_d.items():
... print(k,v)
...
pike 1
apple 3
banana 2
orange 2Heapq
这个模块提供了堆队列算法的实现,也称为优先队列算法。
堆是一个二叉树,它的每个父节点的值都只会小于或等于所有孩子节点(的值)。 它使用了数组来实现:从零开始计数,对于所有的 k ,都有 heap[k] <= heap[2k+1] 和 heap[k] <= heap[2k+2]。 为了便于比较,不存在的元素被认为是无限大。 堆最有趣的特性在于最小的元素总是在根结点:heap[0]。
这个API与教材的堆算法实现有所不同,具体区别有两方面:(a)我们使用了从零开始的索引。这使得节点和其孩子节点索引之间的关系不太直观但更加适合,因为 Python 使用从零开始的索引。 (b)我们的 pop 方法返回最小的项而不是最大的项(这在教材中称为“最小堆”;而“最大堆”在教材中更为常见,因为它更适用于原地排序)。
基于这两方面,把堆看作原生的Python list也没什么奇怪的: heap[0] 表示最小的元素,同时 heap.sort() 维护了堆的不变性!
要创建一个堆,可以使用list来初始化为 [] ,或者你可以通过一个函数 heapify() ,来把一个list转换成堆。
高端操作
正则表达
CGI编程
MySQL
多线程
GUI前端
SMTP
常用快捷键
常见方法
python中的浅拷贝以及python中的深拷贝
浅拷贝:是在另一块地址中创建一个新的变量和容器,但是容器内的元素的地址均是源对象的元素的地址的拷贝。也就是说新的容器中指向了旧的元素
深拷贝:完全拷贝了一个副本,容器内部元素地址都不一样range和xrange的区别
range()是返回一个遍历列表,而xrange()是一个生成器Range函数的一些用法
- 返回一系列连续增加的整数
- 工作方式类似于分片
- 可生成一个列表对象
is 和 == 是否相同
不一样,is是判断两个对象的内存地址是否相同,==判断两个对象的值是否相同lambda函数
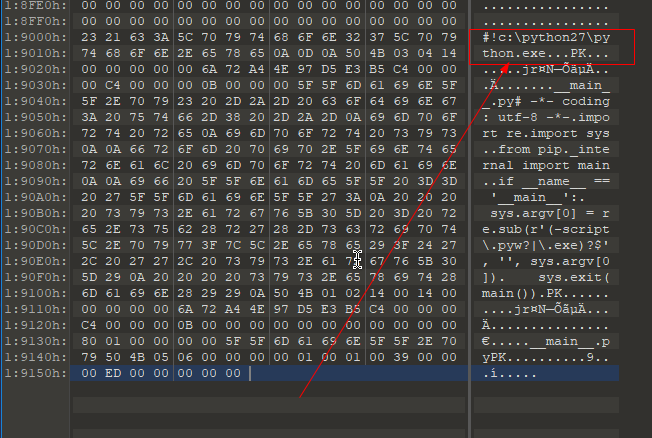
“Fatal error in launcher: Unable to create process using … “
- 原因1:动了系统的环境变量(重装系统或者误删了/移动了python)
- 解决:右键我的电脑——属性——高级系统设置中修改正确的环境变量
- 原因2:如果修改了原因1不成功,则应该是pip或者某个命令模块(我的就是tensorboard)指向的解释器路径有问题
- 解决:原地址重装/伪造一个python解释器(没成功)/直接用010 editor修改模块二进制文件所指向的解释器路径。
![演示]()
- 原因1:动了系统的环境变量(重装系统或者误删了/移动了python)
“freezabel()主函数冻结EOF”
- 缺少启动函数:if name = “main”: