
伊梦碎始
一个简单的复盘记录贴&面经
面试其实是一个双向选择的过程,展现自己的优点,坦诚自己的缺点,可以更好的认识自己,提升自己。同时也要学会揣度对方要的是什么,你自己的亮点和特点在哪,能不能简单清晰地表达清楚。
简历撰写
- 简历与岗位针对性差
要适当根据求职岗位去调整自己简历的内容 - 项目组织形式流水账
切忌不要罗列,要主次分明,突出自己的能力和亮点,特别是一些可以量化的指标要凸显 - 项目介绍杂乱
刚开始我的简历上满是杂乱的项目和成果,虽然突显了工作量,但这并不能让HR立马知道你会些什么,做过什么,大概适合哪些岗位。 - 过多求职无关的内容
与求职无关的内容尽量不要占用到页面的百分之十,只起到一点锦上添花的作用即可。考点
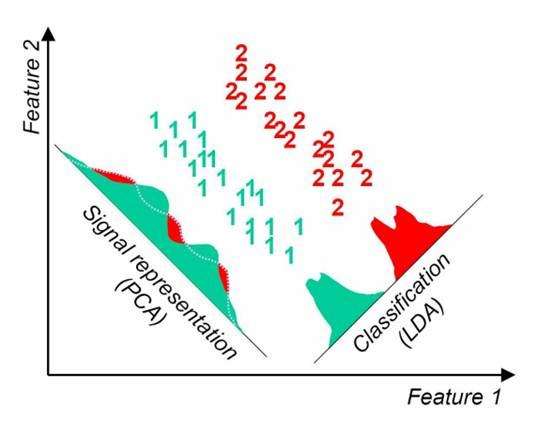
常见的数据降维方式方法
- t-sne 从高维降到低维,代价高昂,但是效果很好
- lda,线性判别降维算法
![LDA-PCA]()
- PCA,方差最大化理论降维方法
gmm中的隐变量是什么
描述模型来自于哪一类高斯分布-
面试
面试的本质:向面试官展示自我,大家双向选择的过程~(心态上大体是这样即可,但有时候做到这句话并不容易)
优胜劣汰,弱肉强食的现实告诉我,真正的平等永远建立在实力的基础上。考察的维度
基础知识扎实
问题解决能力,专业技能优秀
对领域比较敏感,可以解决一些常见的问题创造性能力,前沿技术的敏感度
发现场景下的难点,进一步用前沿的技术解决当前面临的问题系统思考能力
有大局观,在papeline中知道业务的各个关节的联结点,以便更加优秀完善地完成整个系统工程贯穿全场的表达沟通能力
准确get点,看得出自己的对接业务,工作磨合能力~面试的技巧
语速的控制
防止紧张,紧张就会导致语速过快~防止面试官跟不上打断节奏扬长避短
避免在自己熟悉的场景和问题中纠缠。对于自己不熟悉的领域或者问题可以先直接坦言不足,如有把我,并且被允许的话,可以展开相似领域,问题的经历和做法。主动展示,把握节奏
- 熟悉在面试中,可以适当询问面试官在某具体场景下的做法,将单纯的被动面试变成双向交流可以基于相似经历建立共鸣
- 利用项目串接的准备内容,在可控范围内,主动展示自己在某些场景、任务或者某项具体技术点上的实践和系统化思考。树立系统化思考和具有技术深度的形象,把我面试中的大部分时间
- 例子:随机森林下样本类别不平衡怎么办
- 例子:多模态学习的技术点
如何做复盘
- 面试过程中及时记录面试官的问题和自己的回答(务必全程录音)
- 面试结束后,回听一下面试过程,注意如下方面:
- 语速控制
- 哪些项目、哪些关键词引起了面试官的提问
- 针对面试官问题的回答内容
- 确定不足之处:针对面试官的关键词兴趣点和自身的情况,改动/强化项目讲述内容
牛客面经(NLP):我的面试全流程模拟
大概一定会问的问题以及流程,剩下的尽量答了:
自我介绍(用好三板斧,自我介绍算是成了,第一印象很重要)
第一式:我是谁,我来自哪里
我是谁谁谁(气氛和谐的话可以展开一点,大多时候其实没必要),来自哪里,毕业于什么什么大学,想应聘贵公司的暑期实习。
第二式:我做了什么,做成了什么
大学期间,因为学的是自动化专业,很早就接触到了人工智能。伴随着浓厚的兴趣,大二暑假就和同学组队参加了广东省的电子设计大赛(偶数年没有电设国赛),当时纯手工DIY了一台可以和人对话的智能小车,评审时连评委也很惊讶,最后拿了那届比赛中为数不多的一等奖。大三后在学院智能科学系老师的鼓励和支持下,给我的作品立了一个重点项目,让我放手干继续开发。后来,我就在原有的基础上,加入了视觉开始搞起了多模态人机交互,期间拉上几个对Ai也很感兴趣的师弟成立了自己的课题小组,专注于做相关项目的立项和研发,几年来一直都有着不错的成果产出。我读研后在和导师交流沟通后继续开展自己的多模态研究工作,参与在线数字签名认证研究,到现在,在一边学习的同时也一边实现自己的一些idea。
第三式:我以后想要做什么,我的一些个人追求是什么
在以后的工作中,我十分希望也渴望能够继续从事多模态人机交互的研究工作。
《个人介绍稿子》:
常规基础知识
- 机器学习体系
- 用过哪些机器学习算法,怎么实现的。
- 深度学习体系
- BERT以及相关的知识点:transformer、attention、word2vec等
这两天自己手撕一下论文和代码,以及重要的关键技术点 - XXXXXX
- BERT以及相关的知识点:transformer、attention、word2vec等
- 线性代数&概率论
还可以去牛客网查一下自己的知识能不能回答到这些问题。
- 项目/穿插基础
干这一行,项目和论文是重中之重,显示出你的能力和经验,最好还能和目标团队的业务产生联系
提前准备一下项目的介绍:1.项目背景&遇到的问题 2.解决方案|贡献 3.一些可以量化的收益在哪里
项目之中的技术和方法以及思考能不能串起来将,讲出其中的异同和自己的思考:比如我对多模态,多模式,多模型问题的理解
熟透和自己项目涉及的相关技术:
百步梯:为什么会想到用随机森林?
在我看来,随机森林是一种三个臭皮匠顶个诸葛亮的笨方法,但确定对话场景以及对话人的情感状态是用不着诸葛亮的。人也是先天趋向从众的动物,这种情况下,大多数的就是正确的。并且以算法或者计算作为判定基准,缺乏鲁棒性,也很难进行自适应调整和理解。
交互控制时的随机森林改进,是怎么改善数据不平衡下模型分类性能下降的问题的?
回看一下:因为对话场景下,人的情绪特征反应虽然多变,但绝大部分场景下都是平和欢快的日常交流,这就导致了收集到的样本集里通用样本非常之多,极端情绪下的样本非常之少这一数据极不平衡的情况,
为了解决这一情况,我根据人对于新特征输入都会有明显的刺激反应以及结合机器学习里特征权重这一方法,在交互的时间序列上给新特征输入一个相对大的学习权重或者是强化其特征从而进行学习。那个通用场景的百分之80识别率如何得到的,讲讲自己当初是如何设计和搭建这个模型的
这个识别率准确来讲应该是场景的召回率,是通过一定的对话轮数之后,模型自己根据收集到的数据对对话场景(微表情+对话情绪倾向)进行的判定,最终的趋势是收敛在了百分之八十附近(加入各种不同对话场景的对照组情况也类似),当然这么做还是有失严谨的地方,但因为是自己diy出来的模态交互场景,因此当时没能找到较好的数据集进行测试和验证。
你设计的控制-语义双闭环是怎么回事,双闭环有什么优势,是怎么借鉴控制里的经验的?
双闭环是我在学习复杂电机调速控制时得到的灵感,在内环不具备很强抗扰动性能的情况下增加一个外环回路来环节或者消除内环干扰的影响,也就是说在模型对话收集数据的时候,外环会完成上一轮对话的信息的反馈以及当前轮的对话模型决策,把合适的语料交给合适的对话模型,从而提高其性能。
讲讲你引入的反馈机制和自优化的由来(感觉很不专业?)
反馈有两部分,一部分是内环对语料的反馈记录和模型训练,一部分是外环对于场景交互信息(表情、文本情绪倾向)的反馈,有完整的自我学习回路后模型就可以在交互过程中不断获得样本自优化~
你是怎么做NLU的(意图识别、对话管理,对话模型部署)
研究生课题:
说说OSV问题
OSV的目标就是区分出两个签名,真签或者是伪签,本质上是一个求相似度的任务。签名是一种一维时序特征,传统方法就是将其序列化后用孪生神经网络进行模拟和训练,再进行相似度的计算和学习。常用于真伪鉴别,签名鉴定,电子产品的加密保密等领域。
还有你研究的多模态深度学习,你是怎么理解的,进展怎么样
除了之前本科做的多模态特征表示以及后来研究生手写数字签名用的多模态+多模型。也有在做一些VLP模型轻量化的研究工作,比如参考Vilt还有clip进行模型的pre-train和fine-tune等
你是怎么用字段匹配的
要判断两个事物的相似度,出了整体上的相似度计算以外,还要保证局部明显特征上的相似,字段也就是笔画的局部特征,某一笔和其他部分有着明显不同则可以用Attention标注出来,然后进行字段上的特征匹配。
重点为什么这个问题能够采用一维升到二维的方法,你当初是怎么想到的?
在一维相似度上有很多算法可以计算。比如求余弦相似度,求欧式距离等等。大部分都是先用序列将笔画特征连接起来,然后丢给分类器做分类学习,每一个组合序列组合对于计算机来讲是高维特征,不可避免会造成模型计算上的浪费。所以既然要去拼接多个局部特征,为什么不直接用二维矩阵的去表达笔画整体的特征,然后conve出来比较关键的一些局部细节从而得知特征是否相似,二维的矩阵匹配也相比一维上计算相似度有着更好的效果,而且还免去了手工分割的麻烦。
数据集上的表现怎么样,论文怎么样了
基准数据集的T1级别特征上EER都略低于其他算法,T5、T10级则体现出了明显的优势。
我看你用了attention ,有想到过transformer或者是bert么?
有在了解和学习,transformer影响力很大,已经sota了整个NLP,同时在CV攻城略地,多模态又与transformer的统一计算能力十分亲和,bert只用了transformer的一部分,就是encoder结构,在任务型序列或者对话,如机器翻译,知识问答方面一骑绝尘,但生成力略显逊色。
什么是融合路径签名PSS(二维矩阵+局部路径)
就是一个签名不单只有他的二维特征,还有起路径-时间特征,这个也是很具有相似度区分能力的特征。
用了那些数据集,数据是怎么样的,怎么处理的,达到了什么样的效果
- MCYT-100:100个用户,25组正样本和25个熟练伪样本,带有时序标注以及压力、夹角的标注。
- BiosecureID:由 132 个用户组成,每个用户有 16 个真实样本和 12 个熟练的伪造样本,在四个不同的会话中捕获。所有签名均由 Wacom Intuos 数位板以 100 Hz 的采样率采集。
- SUSIG-Visual:SUSIG-Visual 数据集由 100 个用户组成,在两个单独的会话中收集了 20 个真实样本,每个用户有 10 个熟练的伪造样本。
- MOBISIG:MOBISIG 由 83 个用户组成,每个用户有 45 个正品样本和 20 个熟练的伪造样本,使用 ANexus 9 平板电脑以 60 Hz 的采样率在三个不同的会话中捕获。
数据集上表现出来的效果,为什么是你说的SOTA的性能:
对于这些实验,我们首先在 MCYT-100 数据集上训练我们的模型,然后分别在 SUSIG、BiosecureID 和 MOBISIG 数据集的测试集上对其进行评估。由于 MDB-DTW [13] 不适合 T1 场景下的实验,因此我们在 T5 和 T10 场景下进行 CST。结果示于表VI。可以观察到,MDB-DTW 对跨域数据高度敏感,在 T5 和 T10 场景下,三个数据集的平均性能差距分别为 6.02% 和 5.91%。相反,我们的 F2FM 在 T5 和 T10 情景下的平均性能差距分别仅为 1.39% 和 1.31%。这比 MDB-DTW [13] 低五倍。此外,F2FM 的 CST 结果接近甚至优于 SOTA,这证明了我们提出的方法的高泛化能力。
什么是T1,什么是T5、T10等场景
竞赛
你的这款小车作品涉及到了哪些技术,说说看,哪些主要是你做的
主要是一套人机交互技术,包括语言识别,语音合成,对话策略管理,NLP,我主要做的就是搭建整个框架出来还有做NLP相关的对话管理工作,同时也写控制方面的代码。
看代码说代码里的这些功能是怎么实现的,怎么设计和编程
框架有三部分,第一部分是采集信号,第二部分是语言理解和控制处理,第三部分是输出执行,这其实就像一个以自然语言为输入的操作系统或者说软件,我想让机器人实现什么功能,只需要在采集端采集到语音信号,第二部分正确理解意图,最后就是在第三部分进行应用功能开发即可,可以根据需求定制出各式各样的功能。
算法情况,你用了哪些算法
参加比赛时我还处于刚了解Ai的阶段,没有涉及到算法的应用,只有处理对话情绪特征时模拟了一下时间连续变化这一特征。
毕设
- Imagecaption
- 结构:CNN+LSTM+Inception层,也就是CNN作为编码器,LSTM作为解码器,Inception可以作为序列长度转换使用。
- 评价指标:
- CIDEr:这个指标将每个句子都看成是文档,将其表示成Term Frequency Inverse Document Frequency的向量形式,通过对每个n元组进行TF-IDE权值计算,计算参考caption与模型生成的caption的余弦相似度,来衡量
- SPICE:使用基于图的语义表示来编码caption中的objects, attributes 和 relationships。它先将待评价 caption 和参考 captions 用 Probabilistic Context-Free Grammar (PCFG) dependency parser parse 成 syntactic dependencies trees,然后用基于规则的方法把 dependency tree 映射成 scene graphs。最后计算待评价的 caption 中 objects, attributes 和 relationships 的 F-score 值。
- Imagecaption
- 组织
- 为什么想着要带团队
一是想找到志同道合的人一起做研究。二是提高研究和开发的效率,更好地实现一下自己的idea。三是刚开始是奔着创业去的,但因为一些不可抗力被迫放弃了。 - 从中有什么启发和收获
难和累,感觉要做好一件事并不容易,但收获也很多,团队,成果,友谊,青春 - 怎么提高团队/项目的产出速度
这方面感触最深的就是项目甘特图,分工明确的同时也能照顾到各自的进度周期,谁谁谁哪个小组在什么时间内完成什么开发,能够清晰的制定和让成员明确自己的任务就是最好的优化效率的方法。
- 为什么想着要带团队
- 编程
- LRU缓存机制
- 无重复字符的最长子串
- 反转链表
- 两数之和
- 三数之和
- 数组中的第K个最大元素
- 二叉树的层序遍历
- 最大子序和
- 比较版本号
干货面经(2022年春天)
OPPO:
一面:
- 总结:面试官给我的总评大概是:以前做的东西很多很不错,但对于NLP最新的一些东西还不算太了解(比如bert、知识蒸馏、知识图谱等等),很多关键的技术梳理得不够清晰,有点一盘散沙拾不起来的感觉,细节技术点不够熟悉还有对技术的描述方面可以再打磨打磨。
问的点都是顺腾摸瓜,越问越细。如果没有把握圆回来还是不要讲你做了这个事的好,还有自己对一些技术已经不算太熟悉了,比如这个任务怎么做特征,数据是怎么样的,怎么处理中间的label,是不是端到端等等问题,这个行业的面试官最感兴趣的就是你的任务。怎么样分析任务,怎么样处理数据,怎么样训练特征,怎么样得到或者说是转化成自己想要的输出。你的方法的创新点在哪里,用了什么样的数据集得到什么样的效果,你写了那些地方的代码。都是考察的很关键的问题。
还有一个就是熟悉的东西真的都能讲,你之前用的方法虽然有些小的构思不一定很正确(包括做微表情还有文本情感倾向最后得到场景label的这种构思),但你达到了你想要的效果,这对于落地来说也没有什么问题,又不是去刷点写论文。
最后,还是要讲好你的项目的“故事”,主体部分用了什么样的构思,用了什么样的方法,怎么样做的训练和测试甚至是验证,最后得到了什么样的效果。有这样一种实现model以及落地的能力才是企业最看重的。
总之就是,你要对你做过的事情有比较清晰的认知和最好熟悉到里面的所有技术相关的细节,再用那啥star法则像故事一样讲出来,OVER
把你的闪光点侃侃而谈地说来,就卷过了大部分同龄人。
看下面的具体问题。- 问题:
- 有关我做OSV的:问了为什么笔画是一维的数据,不会直接当二维数据去处理么?没有前人做过么? 你是怎么做二维上的特征的,和其他人的区别在哪里?
- 问我EVAI的:怎么实现这个系统构思的,有什么部分,用了什么相关的技术? 自己实现的点在哪里
- 问毕设的:Image caption结构是怎么样的,怎么评估性能,里面的技术搜索是?
- 问前沿的:bert、多模态transformer的、知识图谱、知识蒸馏的等等
HR面:
- 自我介绍
- 生活经历、科研经历提问
- 身边人对我的评价
- 压力大的时候怎么办(抗压方法和能力)
- 学习和科研时间的安排抉择
- 如何处理好人际关系
- 最近对自己影响比较大的一个人
- 喜欢按部就班还是有所创作
泡池子
阿里:
- 电话面:整理聊了自己以前做的一些事情,也顺便梳理了一下所用到技术栈,对于对话系统,我不熟悉的点还有很多,比如表情情绪分类,文本分类,倾向分析是怎么做的。对话是基于什么做的(检索,一个是生成),有很多技术点我的理解都不够深入。只能说一些蛮表面普通的东西。
一些话术有待提高,比如介绍自己的本科时,怎么样凸显出有价值和优秀的地方
- 复习的技术点:
- 模型如何做意图理解(词袋模型)
- 如何做文本情绪倾向(文本分类问题,向量化索引,训练)
- 转部门:阿里集团智能互联团队,搞AloT的(机会难得,这次可要好好准备一次过了)
- 一面(半小时项目+一小时做题)
- 题目:创建一个栈(带getMin)、实现DTW算法(固定使用某种距离)
- 代码的基础底子还是比较薄,很多函数的功能的模块还不一定会使用(时间去堆了,自己的确这块弱)
- 二面(凉经)
- 电话录音复盘,应该是我的机器学习和编程基础过差的原因
字节
- 部门不太相关,就考了简单编程(删除链表某个节点)、还有智力题(8个球天秤找出其中一个最特殊的)
- 给一个target,在链表里找到它并删除
- 八个球除了重量其他一致,一个天平,找出其中重量不同的那个
解法就是如何最快找到找齐正常的球(平的状态),大概的思路就是三个三个称,两个两个称,一个一个称,最后再与正常求做对比。
- 部门不太相关,就考了简单编程(删除链表某个节点)、还有智力题(8个球天秤找出其中一个最特殊的)
网易雷火
面试预热:虚拟人方向
包括全栈人脸AI技术、全栈人体AI技术、情感计算、(跨)多模态计算、多信号融合、视频理解、视频合成、自然语言处理、语音信号处理。 工作内容: 负责/参与围绕人脸(人体)图像/视频合成及理解;包括三维重建,表情重建/迁移,换脸,唇语合成,肢体动作视频合成,情感计算,情绪识别,多模态计算;- 我的关键技术栈:人脸微表情、图像视频理解、情感计算(文本)、多模态信号处理(我的label融合)、语音信号处理(CTC普通话)
- 薄弱环节:pytorch(动态图神经网络)的一些库和核心原理,计算向量和矩阵,没达到熟练的级别、签名认证的模型fusion问题:(Resnet搭起来的CBAM+GRU(本质上是LSTM))
面经:
一面:
- 本质问题:自己的算法方面真的理解不深,甚至有点不懂算法的感觉,很多时候只知道是这么个东西,不知道怎么去用,怎么去优化~
- 一些技巧,缺少听到一个问题,大概知道面试官要考察我哪里的这根筋
- MISS:剪枝说失误,不太清晰的概念还是最好别提,同时也说明自己有时候看似理解,但并不深入理解这个东西。深入在哪,在有一些独特的见解和成效,理解到其背后根本的数学原理。
二面:(有幸进入二面)
- 回顾:整场面试下来其实大多数时间都是
- 总结:自己的优势是在有很相关的虚拟人项目、而且准确表达出了自己对于多模态交互的理解与优化能力。
- 问题:自己对于项目的表达能力、陈述能力还有可以提高的地方,另外有空可以做个PPT去展示我的项目工作。这样清晰易懂一些。
- EVAi项目除了算法可以拓展深入以外,其他方面已经没有太大的问题了
已经没有其他技术面了,希望顺利进HR面吧~
4.6得知面试挂了,这里从挂了的角度总结一下自己的问题:
- 讲项目尽量利用白板或者图描述自己的逻辑
- 算法这种东西还是要考察自己在领域内独特的想法,光会搬用复现可不太行,特别是OSV问题的算法应该扯一点实际的应用理解(比如多模态相似度考量用于推荐和搜索)
- 一点社交法则吧:想一想如何才能掐准不同性格面试官的胃口(当面试官确实不太理解或者不认可自己的工作的时候应该如何相处:貌似只能说面试官的疑问点我尽量答好了)
百度
一面:基础知识不扎实,有些点要记录查阅一下
树相关:(好好去理解才是重点,现在只有一点背的印象)
头节点是怎么生成的,怎么去做的分类
每个节点是根据什么进行分类预测的,熵(经验熵)又是如何进行计算的
决策树与熵
决策树的熵本质上是香农定义的一种随机变量的不确定性度量。如果待分类的事物可能划分在多个分类之中,则符号x1的信息定义为选择其分类的概率的负log形式。通过上面的式子,我们需要计算所有类别所有可能值包涵的信息数学期望,熵越大,随机变量的不确定性就越大。当熵中的概率由数据估计(特别是最大似然估计)得到时,锁对应的熵为经验熵。什么交由数据估计?比如有10个数据,一共有两个类别,A和B类。其中有7个数据属于A,则A类的概率即为7/10,其中有3个数据属于B,则该B类的概率即为10分之三。
基础:
- 梯度消失或者是梯度爆炸的原因
网络层数深了容易导致梯度消失,如果求导小于1每一层求导后都容易导致梯度的信息丢失,多层损失函数求导后容易导致梯度消失;如果大于1,那么随着层数的增加,求出的梯度的更新将以指数形式增加 - 损失函数我不太了解
- sigmiod
本质上是逻辑斯特函数,在0附近有较高的斜率(导数最大也只有1/4)是很容易造成梯度消失的。 - relu
它的主要贡献就是解决了梯度消失和梯度爆炸,而且还方便了计算以及加速了网络训练~(缺点,负数为0,有些神经元无法激活,输出不以零为中心,需要归一化)
- sigmiod
- 梯度消失或者是梯度爆炸的原因
美团
- 一面:机器学习这块的基础还是比较薄弱的
- 基础八股问了个遍,答得七七八八,不算太好
- 编程题,一道模拟压栈出栈判断,一道写位运算除法
- 项目用到的技术栈
- 场景题:节假日销量回归预测
- 一面:机器学习这块的基础还是比较薄弱的
TME
- 优势领域:虚拟人、元宇宙、动作动捕、音频视频识别与合成。
- 预热:面试官关注的点,算法理解-有想法,有模式,能够形成自己的世界观和逻辑上实现自洽
简历上要是自己做过的东西,最好是一步一步的,有自己的理解在里面,加分项:展示自己的音乐素养 - 准备:还是要把自己的项目技术栈和自己的课题过一过,深入的去想一些算法方面的问题
华为
- 经过了五一和消沉了半个月,我已经没有面试状态了,还是好好准备小论文和下半年的秋招吧
- 我的问题应该不能笼统的概括为基础不牢固,而是有一些根本的理解性工作和思考性工作一直没在做,简而言之就是脑子里没有在想这些东西,所以一时间也倒不出什么水来
- 心态有时比什么都重要,心态无了,很多事情也就做不成了
阶段总结:春招实习
今天是二零二二年的五月十七号,将近两个月的找实习也基本宣告结束了,很惨痛的一次经历,总结一下几点原因吧。1.本科所学没有好好吃透以及拿起来,研究生这一年多确实有点混子日了,没有做出什么真正的研究出来,2.自己对于形势判断能力还有待提升。3.面试能力,待人接物的水平还有待提升。4.基础知识过于薄弱