
融合:一个MMDL算法工程师的修养之道
缘得此书:《百面机器学习》,闲来一叙
认知体系搭建:
前言小叙:
在这篇文章中,我会从上述四个维度记录自己作为一个MMDL算法工程师的成长
多模态学习
什么是多模态学习,本质上其实就是多个模态在表示特征上,特征融合上,特征转换上,特征对齐上进行的深度学习,世界本来就是多模态信息共同传递和作用的。
既可以互补消除歧义,也能强化模态之间的语义表达,甚至不同模态之间的结合可以传递出更加复杂的
特征(例如真挚的情感等等),从单一模态走向多模态,是人工智能技术走向通用人工智能的里程碑~
常见多模态模型和算法
Vilt
Cilp
深度学习
基本结构
conv
卷积结构,三个特性:局部感知,权值共享,下采样,可以模仿眼睛视觉关注局部信息以及提取他们的特征,通过共用卷积核的方式完成权值共享,极大减小了计算量。池化也就是下采样,逐渐降低空间尺寸,减小参数量。- Pooling
其实这东西也有防止过拟合的作用,cnn卷出来的数据太复杂了,容易overfit,所以取个有代表性的数字即可,这就是pooling - Resnet
如果从电力电子角度理解,resnet是一个差分放大器。通过间隔连接获得输出与输入之间的一个差分信号,从而获得更具有学习价值的输出。
- Pooling
RNN/lstm
RNN的结构目的是更好地处理序列信息,而且序列中的每一个元素是具有相关性表征的,如果语音语言序列,结构上的大白话就是,每个隐层都会在时间轴上向下一个层输出当前时间的一个权重W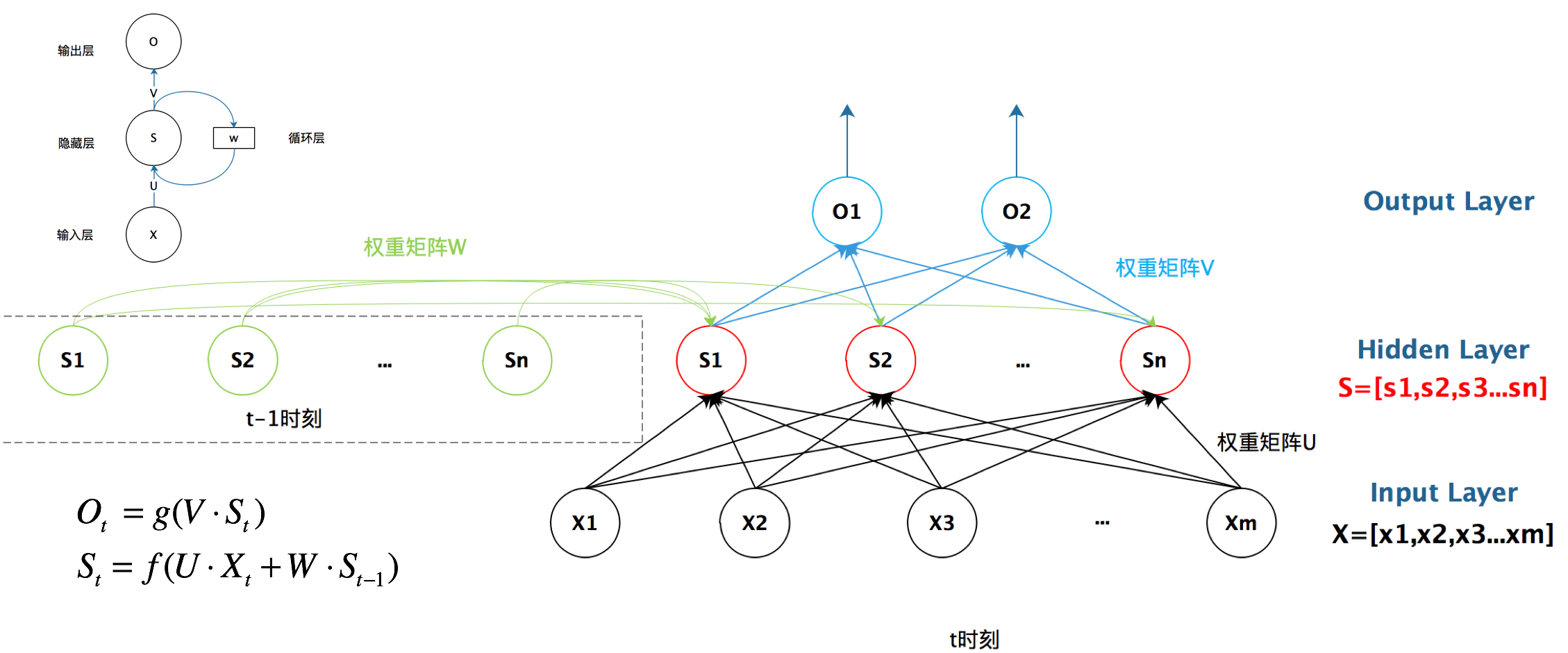
结构特点:- one to one:单输入单输出,例如图像分类
- one to many:给一个输入得到一系列的输出,这种可用于生产图片
- many to one:给一列输入得到一个输出,用于文本分析,情感倾向分析
- many to many:对话机器人
BPTT推导以及梯度消失问题分析
为什么要参数共享:大大减小参数量,简化模型
RNN的输入是序列,如果序列过长,容易导致参数过多而且过拟合,而且RNN每一层对输入的处理是一样的,可以理解成
BN层:推导
Batch Normalization是2015年一篇论文中提出的数据归一化方法,往往用在深度神经网络中激活层之前。其作用可以加快模型训练时的收敛速度,使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失。并且起到一定的正则化作用,几乎代替了Dropout。Relu、Sigmoid
dropout
以一定的概率(一般是0.5)盖住某些隐藏层神经元,使其无法输入和输出参与前向传播和反向传播,减弱模型的复杂度(正则)full link
fc
一些现象
- 维数灾难
在深度学习里,我们的模型往往面对的是高维特征,但随着维度的增加,样本的分布会逐渐小于空间的位置,或者说样本可能分布的位置会远大于样本的数目,这就是维数灾难,容易导致模型overfitting以及不知道从什么方向进行泛化
- 维数灾难
一些常见网络
-
Inception层是Inception网络中的基本结构。Inception层的基本原理如下图:
Inception网络是由多个Inception层组成的,它的最大优点是可以一定程度上帮你省去指定CNN卷积核大小和MP调优的工作。
-

编程应用能力
知识面:
需要知道哪些模型,哪些方法,有什么特点,怎么调整修改,怎么应用
面试问题归总
前言/总而言之
这两本书是我研究生期间攻读深度学习研究相关问题的重要工具书,虽然概念和公式理解起来不容易,但里面的描述十分具体和生动,学习的境界就是把知识先读厚再读薄~
特征工程
什么是特征
特征:事件本体或者事物发生或者变化的规律,也是学习这个任务的基石,机器学的是什么,就是根据特征学出(优化出)网络的权值
特征方案
- 数据不均衡
- 样本权重
特征归一化
归一化可以缩减样本的分布范围,从而缩短梯度下降过程,从而提高迭代速度
| 线性函数归一化 | 线性变换,使结果映射在区间0~1内 |
| 零均值归一化 | 原始数据映射到均值为0、标准差为1的分布上 |
| 注意 | 数据归一化并非万能。梯度下降过程往往涉及归一化,但决策树(信息增益相关)就于此无关 |类别型特征
- 序号编码:处理有大小关系的数字,比如高低给个1,0
- 独热编码:类别间互相独立,而且可以进行稀疏表示,比如血型
- 二进制编码:大类别ID化,将ID编码成为二进制编号
高维组合特征
组合特征:具有复杂关系的特征组合(比如我自己的微表情+语音文本倾向)
在一些推荐系统问题中,特征往往是相关联的,和结果又直接相关,我们也知道,网络可以从基础特征中学习得到一些高维度的特征表达
处理方法:以逻辑回归为例子,假设数据有k维的特征向量,k之中两两可以组成特征,这种两两组合特征的学习很容易提高参数的维度,例如在预测网页商品点击率的时候,每个用户都要有对应点击所有的商品的样本,所有用户就是m*n的一个大小,如果还是海量规模的用户数据,这种参数量根本无法学习
所以采用k维度的低维特征表达所有的m,和所有的n,这样参数就是km+kn,等价于矩阵分解。文本的特征表示(word2vec)
- 词袋模型
- 把一段文字看成是一袋子词,忽略其中的顺序。把一个单词表示成整段文字这个长向量中的一维。然后给该维度附一个权重值代表其对这段话的重要程度,用逆文本频率TF-IDF计算:[公式]
- N-gram:有些通常连续出现的固定搭配和表达。通常也可以将他们组成一个完整单独的特征放到向量表示中,构成N-gram
- 词干抽取:同一个词可能有多种词性变化,却有相同的含义,实际中就会进行词干抽取统一成一个统一的词干表达
- 主题模型
- 从文本库中发现有代表性的主题(得到主题上面的分布特性),并且能够计算出每篇文章的主题分布
- 词嵌入模型
- 准确率的局限性
$$Accurancy=\frac{n_{correct}}{n_{total}}$$
又公式可以得知,准确率就是分类正确个数占分类总样本个数的比值,所以,当样本类比比例极端不均衡时,准确率往往受占大头的类别的影响,比如99的负样本,1个正样本的情况。 - 精准率与召回率
$$Precosion=\frac{n_{correct}}{n_{model_correct_total}}$$
$$Recall=\frac{n_{correct}}{n_{data_correct_total}}$$ - P-R曲线的作用
P指的是模型的precision,也就是预测的精度,recall也就是召回的精度。,PR曲线的横轴是召回率,纵轴是精确率。对于排序模型来说,pr曲线一个点代表某一阈值下,模型将大于其阈值的判定为正样本,小于的判定为负样本。整条曲线随着阈值从高到低变化(原点附近代表阈值最大)。所以PR曲线完成了对模型的整体性能评估 - 平方根误差:RMSE指标
RMSE = 根号(y预测与y真实之差的平方求和再除以样本数):总体偏差
可以知道,这样的偏差一定很受到离群点的影响,而且越远越离谱,但如果很好地处理了离群点
那么可以这个指标很容易就反映出实际预测与样本的偏差。
当然,还有一个百分比指标:MAPEROC曲线
ROC曲线的横坐标是假阳性率,纵坐标是真阳性率MAE\MSE\RMSE\R LOSS分析
MAE 平均绝对误差
MSE 平方误差
RMSE 均方根误差
R方 决定系数
与平均绝对误差(MAE)相比,平均平方误差(MSE)和均方根误差是对大的预测误差的惩罚。然而,RMSE比MSE广泛用于评估回归模型与其他随机模型的性能,因为它与因变量(Y)的单位相同。
MSE是一个可微分的函数,与MAE这样的不可微分的函数相比,它容易进行数学运算。因此,在许多模型中,尽管RMSE比MAE更难解释,但还是被作为计算损失函数的默认指标。
MAE、MSE和RMSE的值越低,意味着回归模型的准确性越高。然而,较高的R平方值被认为是模型的解释性更强。
R平方和调整后的R平方用于解释线性回归模型中的自变量对因变量变化的解释程度。R平方值总是随着自变量的增加而增加,这可能导致在我们的模型中增加多余的变量。然而,调整后的R平方值解决了这个问题。
调整后的R平方考虑到了预测变量的数量,它被用来确定我们模型中独立变量的数量。如果增加的变量对R平方的增加不够明显,那么调整后的R平方值就会减少。
对于比较不同线性回归模型之间的准确性,RMSE是比R平方更好的选择。
误差估计
- 经验最小化误差
机器学习的目的就是根据一些训练样本,寻找一个最优的函数,使得函数对输入X的估计Y’与实际输出Y之间的期望风险(可以暂时理解为误差)最小化。
期望风险最小化依赖于样本的输入X与其输出Y之间的函数映射关系F(x,y),而这个映射关系,在机器视觉和模式识别系统中,一般指代先验概率和类条件概率。
然而,这两者在实际的应用中,都是无法准确获取的,唯一能够利用的就只有训练样本的输入X及其对应的观测输出Y。
而机器学习的目的又必须要求使得期望风险最小化,从而得到需要的目标函数。不难想象,可以利用样本的算术平均来代替式理想的期望,于是就定义了下面的式子来作为实际的目标风险函数是利用已知的经验数据(训练样本)来计算,因此被称之为经验风险。
用对参数求经验风险来逐渐逼近理想的期望风险的最小值,就是我们常说的经验风险最小化(ERM)原则。
显然,利用经验风险来代替真实的期望风险是有代价的。首先,经验风险并不完全等于期望风险;其次,用经验风险来近似代替期望风险在理论上并没有完善的依据;最后,用经验风险来代替期望风险计算得到的误差属于经验误差,而并非真实期望误差;尽管有这样那样的问题存在,在先验概率和类条件概率无法准确获取的情况下,用经验风险来“想当然”的代替期望风险从而解决模式识别等机器学习问题的思路在这一领域依然大量存在。
2. 降低过拟合的方法:
- 增加数据
- 降低模型复杂度
- 正则化
- 集成学习方法
- 降低欠拟合方法
- 添加新特征
- 增加模型复杂度
- 减小正则化系数
经典算法
SVM
问题一:空间线性可分的两类点,分别向SVM分类超平面投影,这些投影仍然线性可分吗?(p52)
不一定,通过超平面分开的两类点有可能是通过核函数映射后区分开的,如果原本就线性可分,也就不再需要到核函数映射(超平面方法),因为超平面为支持向量间间隔最大分类面,如果样本在其上的投影依然线性可分,显然应存在更优的超平面,故与假设矛盾,反之可推出映射到超平面的样本一定是线性不可分的两类点。
问题二:是否存在一组参数使得SVM训练误差为0?
问题三:训练误差为0的SVM分类器一定存在么?加入松弛变量呢?
逻辑回归
线性回归
在一堆数据点中用最小二乘法拟合出数据点的近似曲线
问题一:逻辑回归与线性回归有什么不同?
本质与线性回归大相径庭(相差很远),最重要的一点就是,逻辑回归处理的其实是分类问题,。逻辑回归中的因变量是离散的,线性回归中的因变量是连续的。相同的地方是都用了极大似然的方法对样本惊醒了建模
问题二:如何处理多分类问题,有哪些常见的做法?应用于什么场景
多分类问题往往采用多项逻辑回归来进行分类
决策树与随机森林
决策树
决策是广泛使用的分类算法,相比贝叶斯,决策树的优势在于不需要提供先验参数,所以在学习未知的知识这一情况下更加适用
当一条记录有若干不同的方式划分为目标类的一部分时,适合用单条线来发现类别之间边界的统计学方法是无力的。而决策树能够成功地达到这一目标。
决策规则
决策树可以认为是if-then的集合,也可以认为是点贵在特征空间与类空间上的条件概率分布。其主要有点事模型具有很好的可解释性,分类速度快。
决策树的学习
决策树的学习与预测过程:学习时,利用训练数据,根据损失函数最小化的原则简历决策树模型;预测时,对新的数据,利用决策树模型进行分类。决策树学习通常包括3个步骤:特征选择、树生成、树修剪。
以下是决策树学习伪代码
1 | |
显然,决策树的生成是一个递归的过程。在决策树的基本算法中,有三种递归返回的情况:
(1) 当前节点包涵的样本全属于同一类别,无需划分
(2) 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分
(3) 当前结点包含的样本集为空,不能划分
在第(2)中情况下,我们把当前节点标记为叶结点,但把其类别设定为该节点所含样本最多的类别;
在第(3)中情况下,同样把当前节点标记为叶结点,但把其类别设定为父节点所含样本最多的类别;
特征选择:信息增益/率与基尼指数
信息增益表示得知特征X的信息而使类Y的信息的不确定性减少的程度。
基尼指数Gini(D)表示集合D的不确定性,基尼指数Gini(D,A)表示经A=a分割后,集合的不确定性。尼基指数越大,样本的集合不确定性越大,这一点与熵类似。
决策树剪枝
决策树生成算法递归地产生决策树,直到不能继续下去为止。这样产生的树往往对训练数据的分类很准确,但对未知的测试数据的分类却没有那么准确,即出现过拟合现象。解决这个问题的办法是考虑决策树的复杂度,对已经生成的决策树进行简化。
预剪枝
预剪枝的本质就是用验证集对分支节点的预测或者下一预测进行评估,如果分类错误的话,则直接去掉这一分支的展开,这就是预剪枝
对比上面的未剪枝决策树和上图(预剪枝决策树),可以看出,预剪枝决策树使得决策树的很多分支都没有“展开”,这不仅降低了过拟合的风险,还显著少了决策树的训练时间开销和测试时间开销。但另一方面,有些分支的当前划分虽不能提升泛化性能、甚至可能导致泛化性能暂时下降,但在其基础上进行的后续划分,却有可能导致性能显著提高;预剪枝基于“贪心”本质禁止这些分支展开,给预剪枝决策树带来了欠拟合的风险。
后剪枝
后剪枝过程描述
后剪枝先从训练集生成一棵完整决策树,把在验证集上表现不良的子树分支减掉
优缺点
- 优点
可解释性强
可处理混合类型特征
具体伸缩不变性(不用归一化特征)
有特征组合的作用
可自然地处理缺失值
对异常点鲁棒
有特征选择作用
可扩展性强, 容易并行 - 缺点
缺乏平滑性(回归预测时输出值只能输出有限的若干种数值)
不适合处理高维稀疏数据
降维方法
其实嘛,降维的本质很单纯,就是奥特卡姆剃刀理论,有一维没啥用,还凭空增加计算量。也就是说原本是三维的点,但仔细一看其实他们都在一个平面上,那就降维到二维进行分类即可。其他维数同理
PCA最大方差理论
信息有大方差,噪声有小方差
所以PCA的目标就是寻找最大化投影方差,那怎么找呢?
原理上:投影肯定需要投影方向,那我先假设一个投影方向w,之后就变成了根据最大方差求解w的最优化问题,代入求方差的表达式中,可以得知方差的大小和样本的协方差矩阵相关,因为w是单位向量,所以等于求协方差矩阵特征值最大,最佳的投影方向就是最大特征值所对应的特征向量。
方法:(1)中心化处理(2)协方差矩阵(3)特征值分解
EM算法
EM(expectation maximization)期望极大算法
使用场景:高斯混合模型,抛硬币模型
HMM隐马尔科夫模型
基本概念
概率计算方法
学习算法
预测算法
CRF条件随机场
条件随机场是给定随机变量X的条件下,随机变量Y的马尔科夫随机场
降维
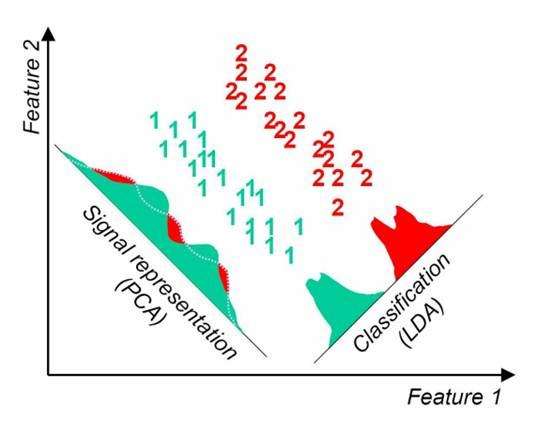
PCA主成分分析
主成分分析(Principal Component Analysis):一种统计方法,它对多变量表示数据点集合寻找尽可能少的正交矢量表征数据信息特征。也是方差最大化理论降维方法![LDA-PCA]()
lda,线性判别降维算法
不同于PCA方差最大化理论,LDA算法的思想是将数据投影到低维空间之后,使得同一类数据尽可能的紧凑,不同类的数据尽可能分散。因此,LDA算法是一种有监督的机器学习算法。同时,LDA有如下两个假设:- 原始数据根据样本均值进行分类。
- 不同类的数据拥有相同的协方差矩阵。
当然,在实际情况中,不可能满足以上两个假设。但是当数据主要是由均值来区分的时候,LDA一般都可以取得很好的效果。
流形学习
流形学习(manifold learning)是机器学习、模式识别中的一种方法,在维数约简方面具有广泛的应用。它的主要思想是将高维的数据映射到低维,使该低维的数据能够反映原高维数据的某些本质结构特征。流形学习的前提是有一种假设,即某些高维数据,实际是一种低维的流形结构嵌入在高维空间中。流形学习的目的是将其映射回低维空间中,揭示其本质。
t-sne 从高维降到低维,代价高昂,但是效果很好
非监督学习
聚类-kmeans
k均值聚类的算法是一个迭代的过程,每次迭代包括两个步骤:
- 首先选择个类的中心,将样本逐个指派到与其最近的中心的类中,得到一个聚类的结果;
- 然后更新每个类的样本的均值,作为类的新的中心
重复以上步骤,直到样本都分类正确,模型收敛为止。
初始点怎么选?
随机选一个初始点,选个最远点,再选一个距离前两个点最近距离最大的点。如此往复,直至选出K个初始类簇中心点。
k如何选
只要我们假设的类簇的数目等于或者高于真实的类簇的数目时,该指标上升会很缓慢,而一旦试图得到少于真实数目的类簇时,该指标会急剧上升。类簇指标 作为一个重要的参考指标。
类簇的直径是指类簇内任意两点之间的最大距离。
类簇的半径是指类簇内所有点到类簇中心距离的最大值。
最近邻分类算法(K N N)
K N N即K-Nearest Neighbor,是一种memory-based learning,也叫instance-based learning,属于lazy learning。即它没有明显的前期训练过程,而是程序开始运行时,把数据集加载到内存后,不需要进行训练,就可以开始分类了。 K N N也是一种监督学习算法,通过计算新数据与训练数据特征值之间的距离,然后选取K(K>=1)个距离最近的邻居进行分类判(投票法)或者回归。若K=1,新数据被简单分配给其近邻的类。
聚类评价
聚类有两种评价方式,一种是基于外部的评价(就是根据label的分布,看聚类数据的效大体果)
另一种是没有外部信息,纯看聚类簇之间的距离,相似度,间隔性以及紧密性。
高斯混合模型
高斯混合模型(Gaussian Mixture Model)通常简称GMM,是一种业界广泛使用的聚类算法,该方法使用了高斯分布作为参数模型,并使用了期望最大(Expectation Maximization,简称EM)算法进行训练。
高斯分布与使用
高斯分布有时候(一些条件下)又称为正态分布,是一种在自然界大量的存在的,最为常见的分布形式。
EM算法训练
模型的EM训练过程,直观的来讲是这样:我们通过观察采样的概率值和模型概率值的接近程度,来判断一个模型是否拟合良好。然后我们通过调整模型以让新模型更适配采样的概率值。反复迭代这个过程很多次,直到两个概率值非常接近时,我们停止更新并完成模型训练。
现在我们要将这个过程用算法来实现,所使用的方法是模型生成的数据来决定似然值,即通过模型来计算数据的期望值。通过更新参数μ和σ来让期望值最大化。这个过程可以不断迭代直到两次迭代中生成的参数变化非常小为止。该过程和k-means的算法训练过程很相似(k-means不断更新类中心来让结果最大化),只不过在这里的高斯模型中,我们需要同时更新两个参数:分布的均值和标准差
高斯混合(GMM)
高斯混合模型是对高斯模型进行简单的扩展,GMM使用多个高斯分布的组合来刻画数据分布。
举例来说:想象下现在咱们不再考察全部用户的身高,而是要在模型中同时考虑男性和女性的身高。假定之前的样本里男女都有,那么之前所画的高斯分布其实是两个高斯分布的叠加的结果。相比只使用一个高斯来建模,现在我们可以用两个(或多个)高斯分布。
该公式和之前的公式非常相似,细节上有几点差异。首先分布概率是K个高斯分布的和,每个高斯分布有属于自己的μ和σ 参数,以及对应的权重参数,权重值必须为正数,所有权重的和必须等于1,以确保公式给出数值是合理的概率密度值。换句话说如果我们把该公式对应的输入空间合并起来,结果将等于1。
kmeans思想与GMM
在特定条件下,k-means和GMM方法可以互相用对方的思想来表达。在k-means中根据距离每个点最接近的类中心来标记该点的类别,这里存在的假设是每个类簇的尺度接近且特征的分布不存在不均匀性。这也解释了为什么在使用k-means前对数据进行归一会有效果。高斯混合模型则不会受到这个约束,因为它对每个类簇分别考察特征的协方差模型。
K-means算法可以被视为高斯混合模型(GMM)的一种特殊形式。整体上看,高斯混合模型能提供更强的描述能力,因为聚类时数据点的从属关系不仅与近邻相关,还会依赖于类簇的形状。n维高斯分布的形状由每个类簇的协方差来决定。在协方差矩阵上添加特定的约束条件后,可能会通过GMM和k-means得到相同的结果。
实践中如果每个类簇的协方差矩阵绑定在一起(就是说它们完全相同),并且矩阵对角线上的协方差数值保持相同,其他数值则全部为0,这样能够生成具有相同尺寸且形状为圆形类簇。在此条件下,每个点都始终属于最近的中间点对应的类。(达观数据 陈运文)
在k-means方法中使用EM来训练高斯混合模型时对初始值的设置非常敏感。而对比k-means,GMM方法有更多的初始条件要设置。实践中不仅初始类中心要指定,而且协方差矩阵和混合权重也要设置。可以运行k-means来生成类中心,并以此作为高斯混合模型的初始条件。由此可见并两个算法有相似的处理过程,主要区别在于模型的复杂度不同。
整体来看,所有无监督机器学习算法都遵循一条简单的模式:给定一系列数据,训练出一个能描述这些数据规律的模型(并期望潜在过程能生成数据)。训练过程通常要反复迭代,直到无法再优化参数获得更贴合数据的模型为止。
概率图模型
优化算法
采样
前向神经网络
循环神经网络
强化学习
集成学习
生成对抗网络
生成对抗本质上是一种minimax游戏(两个网络分别博弈和优化):存在生成器和判别器两大通道,不断切换通道缩减各自的目标误差并进行对抗。
GANs的值函数:
热门应用
后记
实战详解
数学基础
微积分
线性代数
概率统计与信息论
数值计算与优化
梯度下降
概率图模型
计算机基础
编程基础
算法基础
简单算法
- 如何实现一个优先级队列?
- 如何判断两个链表是否相交?以及查找其第一个交点
- 双指针遍历+哈希表查重
- 遍历两个链表,判断尾指针是否相等
- 如何实现一个LRU
- 双向链表+哈希
- 巧用Map,其放入是按顺序的,最新放入的数据在迭代器最后,而且map的entries方法还有keys方法会返回一个迭代器,迭代器调用next也是顺序返回,所以返回第一个的值就是最老的,找到删除即可
- 三数之和为N的问题
- 数组排序后按nums[i]循环双指针遍历求nums[N-i]
- 全排列、全组合函数
就是将排列组合公式应用化 - 求数组中的TOPK
求数组中的前N个最大的数 - 如何实现各种排序(7类)
- 简述 bloomfilter,及它的使用场景是什么
- 什么是一致性哈希,可以解决什么问题
计网
操作系统
http
shell
git
vim