
【基础】Machine Learning:Base of MMDL
你能够站在巨人肩膀上,往往说明巨人比你高大,头顶星空,脚踏土地
机器学习
ML里的一点哲学问题
NFL:No Free Lunch
这个思想讲的不是模型代价的问题,而是进行优化和评估的问题“:假设所有数据的分布可能性相等,当我们用任一分类做法来预测未观测到的新数据时,对于误分的预期是相同的。” 简而言之,NFL的定律指明,如果我们对要解决的问题一无所知且并假设其分布完全随机且平等,那么任何算法的预期性能都是相似的。
![NFL]()
最简化的艺术:奥卡姆剃刀
核心可以概括为一句话:“如无必要,勿增实体”。用通俗的语言来说,如果两个模型A和B对数据的解释能力完全相同,那么选择较为简单的那个模型。在统计学和数学领域,我们偏好优先选择最简单的那个假设,如果与其他假设相比,其对于观察的描述度一致。
![AOKAMU]()
集成学习:三个臭皮匠原理(追求通用,不求最优)
集成学习的思想无处不在,比较著名的有随机森林等。从某种意义上说,神经网络也是一种集成学习,每个单独的神经元都可以看做某种意义上的学习器。这种方法的精髓在于其假设“子分类器”的错误互相独立,随着子分类器的数目上升,木分类器的误差将会以指数级下降,直到为0。
然而,这样的假设是过分乐观的,因为我们无法保证”子分类器”的错误是相互独立的。以最简单的Bagging为例,如果为了使k个子分类器的错误互相独立,那么我们将训练数据N分为k份。显然,随着k值上升,每个分类器用于训练的数据量都会降低,每个子训练器的准确性也随之下降。即使我们允许训练数据间有重采样,也还是无法避免子分类器数量和准确性之间的矛盾。周志华老师曾这样说:”个体学习的准确性和多样性本身就存在冲突,一般的,准确性很高后,想要增加多样性,就得要牺牲准确性。事实上,如何产生并结合好而不同个体学习器,恰是集合学习的研究核心。”那么,集成学习似乎和前面提到的奥卡姆剃刀定理相违背。明明一个分类模型就够麻烦了,现在为什么要做更多?这其实说到了一个很重要观点,就是奥卡姆剃刀定理并非不可辩驳的真理,而只是一种选择方法。从事科学研究,切勿相信有普遍真理。人大的周孝正教授曾说:”若一件事情不能证实,也不能证伪,就要存疑。” 恰巧,奥卡姆定理就是这样一种不能证实也不能证伪的定理。
民主自由与专制下的集成学习算法
民主:弱分类器融合成为一个强力的主体(投票):random forest
专制:强分类器融合(独裁集团):最强说了算(dynamic classifier selection)、强强融合出更强(stacking)谈不上谁更好更差,人类不同时期需要不同的体制来进行生产和发展,比如生产力水平总体较低,个体认知水平差异很大、民智尚未开启的时代,专制是有效的。当进入现代,生产力大发展,信息高速传播,人人都有了个体的独立思想,要想提高效率,必须采用民主的方式进行决策。
【斗胆预测】:好的体制既不可能绝对民主,也不可能都用专制,而是在符合大部分成员利益的情况下,采用权重式的民主,大平均的专制。
贝叶斯老头:不可知论
无论是机器学习还是统计学习都是一种寻找一种映射f(x),或者更广义的说,进行参数估计。以线性回归为例,我们得到结果仅仅是一组权重。如果我们的目标是参数估计,那么有一个无法回避的问题…参数到底存不存在?换句话说,茫茫宇宙中是否到处都是不确定性(Uncertainty),而因此并不存在真实的参数,而一切都是处于运动当中的。
频率学派(Frequentism)相信参数是客观存在的,虽然未知,但不会改变。因此频率学派的方法一直都是试图估计“哪个值最接近真实值”,相对应的我们使用最大似然估计(Maximum Likelihood Estimation),置信区间(Confidence Level),和p-value。因此这一切都是体现我们对于真实值估算的自信和可靠度。
而贝叶斯学派(Bayesian)相信参数不是固定的,我们需要发生过的事情来推测参数,这也是为什么总和先验(Prior)及后验(Posterior)过不去,才有了最大后验(Maximum a Posteriori)即MAP。贝叶斯学派最大的优势在于承认未知(Uncertainty)的存在,因此感觉更符合我们的常识“不可知论”。从此处说,前文提到的周孝正教授大概是贝叶斯学派的(周教授是社会学家而不是统计学家)。
据我不权威观察,不少统计学出身的人倾向于频率学派而机器学习出身的人更倾向于贝叶斯学派。比如著名的机器学习书籍PRML就是一本贝叶斯学习,而Murphy在MLAPP中曾毫无保留的花了一个小节指明频率学派的牵强之处。
矛盾带来平衡,也是一种美感
随着学习的深入,“统计学习”和“机器学习”之间的区别,也是一种矛盾:模型可解释性与有效性的矛盾。还包含“模型精度”和“模型效率”的矛盾,“欠拟合”和“过拟合”的平衡等。
大部分科学,比如数学还是物理,走到一定程度,都是矛盾互相妥协,都有妥协带来的美感。这给我们的指导是:当我们听到不同的想法的时候,反驳之前先想一想,不要急着捍卫自己的观点。而相反的两种观点,在实际情况下却往往都有不俗的效果,这看似矛盾但却是一种和谐。
因此,当面对纷杂的信息,各种似是而非的解释与结论时。最重要的不是急着发表观点,而是静下来慢下来,不要放弃思考。只有独立的思考,才能最终帮助我们摆脱重重迷雾,达到所追寻的真理。


三要素:模型、策略、算法
模型
在统计学中,模型就是要求学习一个问题的条件概率分布(最优种瓜模型:模型学习土地肥沃程度分布数据,当一批瓜种输入进来,就可以得到对应的最优配瓜位置,刘华强直呼内行)、或者是决策函数,模型的假设空间包含所有可能的条件概率分布或决策函数。例如,假设决策函数是输入变量的线性函数,那么模型的假设空间就是所有这些线性函数构成的函数集合。假设空间中的模型一般有无穷多个。eg:$$F={f \mid Y=f(X)}$$策略
有了模型的假设空间,统计学习接着需要考虑的是如何识别最优以及学习的准则是什么?考虑到什么才是学习完成的标志,这里就是用了自动化方法,损失函数loss以及风险期望损失(人为定义),学习的目标也就是求风险最小模型(模型loss趋近于0),其中,模型关于训练数据集的平均损失成为经验风险或者经验损失,根据大数定律,当样本趋近无穷时,经验风险趋近于期望风险,所以二者是估计的关系,用经验风险估计期望风险。- 经验风险与结构风险
当样本很小时,采用经验风险容易overfitting,这时候要给予结构上的纠偏,也叫正则化,得到结构风险。根据模型的负责度(假设空间上的泛函)指定正则项,从而约束某些变量在学习过程中取到的误差点
- 经验风险与结构风险
算法
算法是指机器学习模型的具体计算方法。
机器学习基于训练数据集,根据学习策略,从假设空间中选择最优模型,最后需要考虑用什么样的计算方法求解最优模型。
这时,机器学习问题归结为最优化问题,机器学习的算法成为求解最优化问题的算法。如果最优化问题有显式的解析解,这个最优化问题就比较简单。但通常解析解不存在,这就需要用数值计算的方法求解。如何保证找到全局最优解,并使求解的过程非常高效,就成为一个重要问题。机器学习可以利用已有的最优化算法,有时也需要开发独自的最优化算法。
机器学习方法之间的不同,主要来自其模型、策略、算法的不同。确定了模型、策略、算法,机器学习的方法也就确定了。这也就是将其称为机器学习三要素的原因。
过拟合与欠拟合
在数据科学学科中,过拟合(overfit)模型被解释为一个从训练集(training set)中得到了高方差(variance)和低偏差(bias),导致其在测试数据中得到低泛化的模型。
偏差作为与方差相对的一个概念,表示了我们基于数据所做出的假设的强度(有效性)。在前文我们尝试学习英语的例子中,我们基于一个没有初始化的模型 ,并把作家的作品当作学习语言的教科书。低偏差看似是一个正向的东西,因为我们可能会有这样的想法:我们并不需要去带着倾向性思维看待我们的数据。然而我们却需要对数据表达的完整性持怀疑态度。因为任何自然处理流程都会生成噪点,并且我们无法自信地保证我们的训练数据涵盖了所有这些噪点。
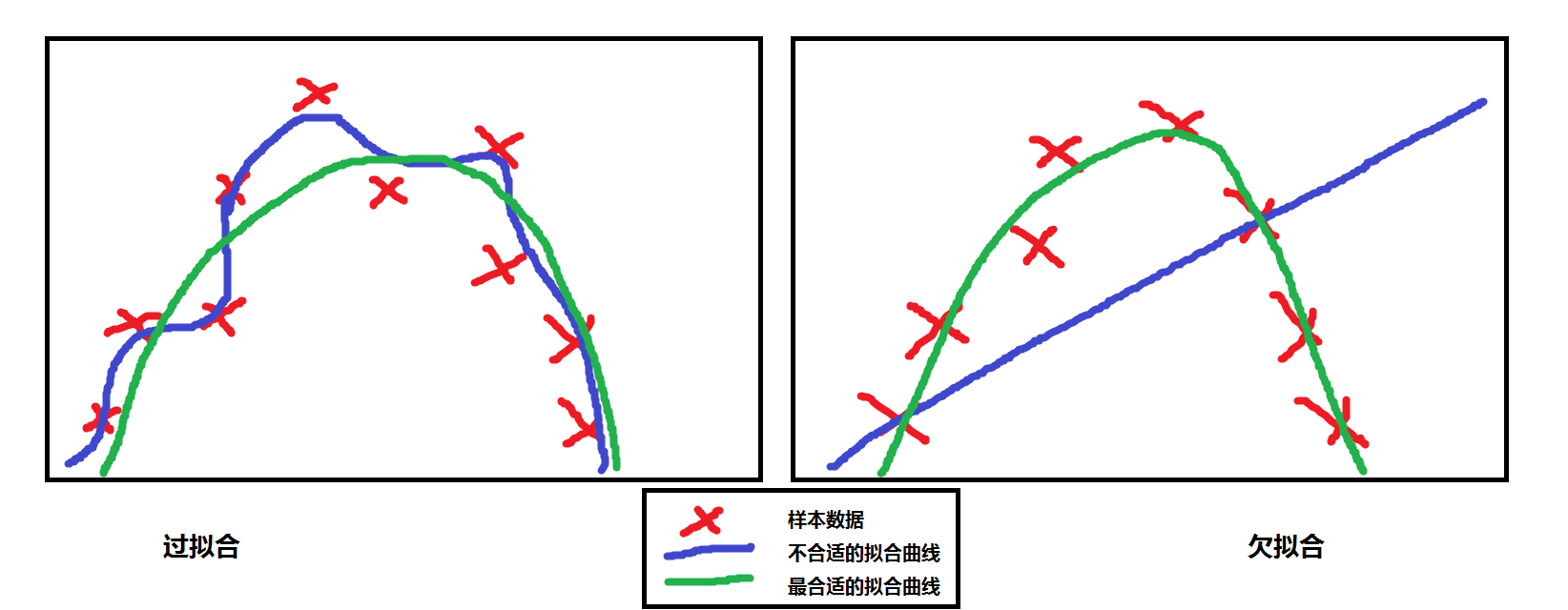
刚才我们了解到了过拟合的模型具有高方差、低偏差的特点。那么相反的情况:低方差、高偏差的模型被称作欠拟合。相较于之前与训练数据紧密贴合的模型,一个欠拟合模型忽视了从训练数据中获得的信息,进而使其无法找到输入和输出数据之间的内在联系。
验证集的作用(val):
在数据科学中,有一个很好的解决方案,叫作“验证(Validation)”。一般训练我们只使用了一个训练集和一个测试集。这意味着我们无法在实战前知道我们的模型的好坏。最理想的情况是,我们能够用一个模拟测试集去对模型进行评估,并在真实测试之前对模型进行改进。这个模拟测试集被称作验证集(validation set),是模型研发工作中非常关键的部分。
正则化
正则化技术广泛应用在机器学习和深度学习算法中,其本质作用是防止过拟合、提高模型泛化能力。过拟合简单理解就是训练的算法模型太过复杂了,过分考虑了当前样本结构。其是防止过拟合的其中一种技术手段。在早期的机器学习领域一般只是将范数惩罚叫做正则化技术,而在深度学习领域认为:能够显著减少方差,而不过度增加偏差的策略都可以认为是正则化技术,故推广的正则化技术还有:扩增样本集、早停止、Dropout、集成学习、多任务学习、对抗训练、参数共享等
过拟合的时候,拟合函数的系数往往非常大,而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
为什么过拟合的时候系数会很大? 如下图所示,过拟合,就是拟合函数需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。
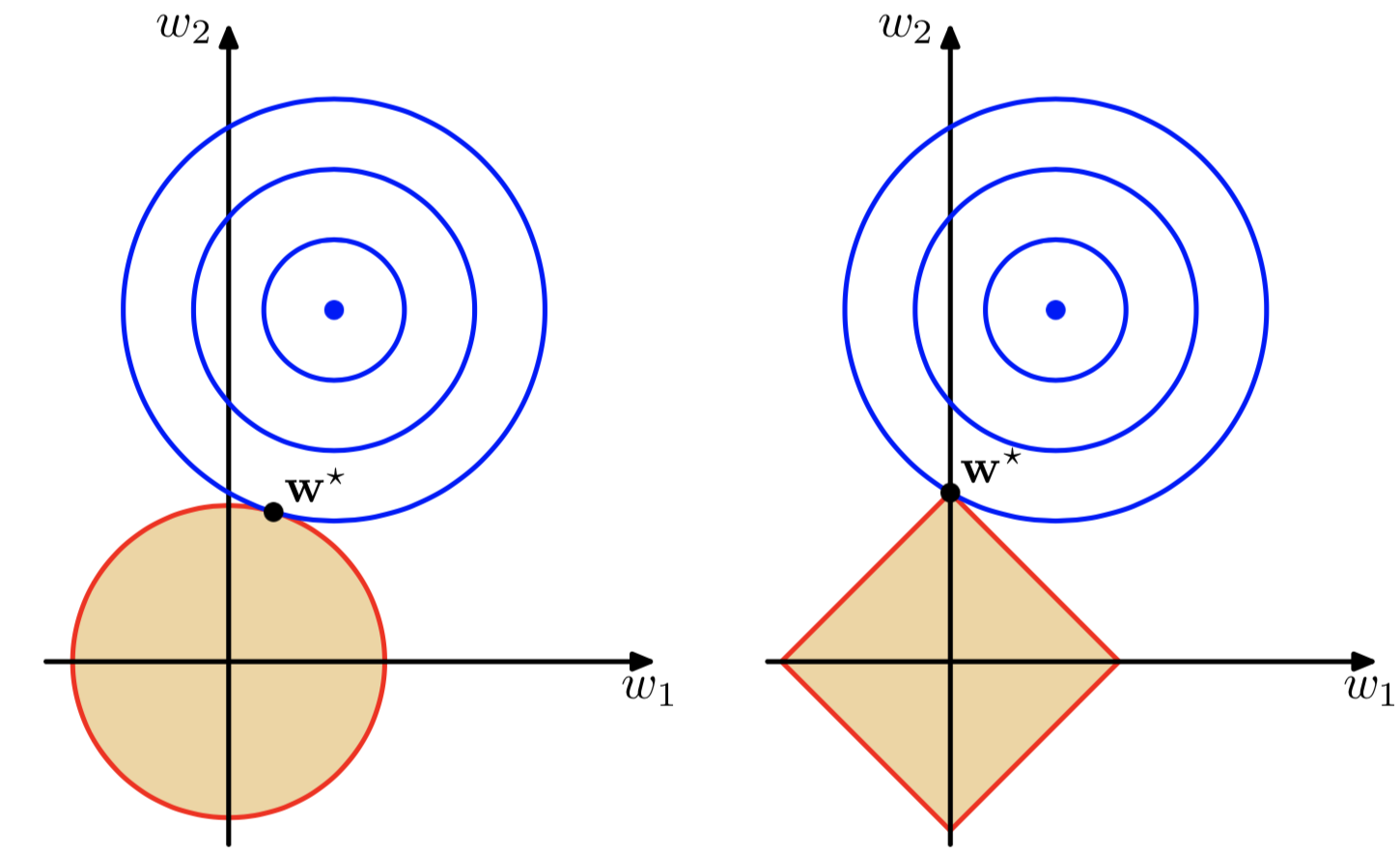
- L1,L2z正则化
- 正则项对应约束条件的最优化
对于模型权重系数w求解是通过最小化目标函数实现的,既求解:
模型性能度量
对学习器的泛化性能进行评估,不仅需要有效可行的实验估计方法,还需要有衡量模型泛化能力的评价标准,这就是性能度量
出了最常用的均方误差用于回归任务之外,还可以用错误率与召回率作为指标
错误率与精度
错误率和精度是分类任务中最常见的两种性能度量,适用于多分类任务,错误率是分类错误的样本数占样本总数的比例,精度则是分类正确的样本数占样本总数的比例。查准率P、查全率R与PR曲线
错误率和精度虽常用,但并不能满足所有任务需求。以西瓜问题为例,假定瓜农拉来一车西瓜,我们用训练好的模型对这些西瓜进行判别,显然,错误率衡量了有多少比例的瓜被判别错误。但是若我们关心的是”挑出的西瓜中有多少比例是好瓜”,或者”所有好瓜中有多少比例被挑了出来”,那么错误率显然就不够用了,这时需要使用其他的性能度量。类似的需求在信息检索、Web搜索等应用中经常出现,例如在信息检索中,我们经常会关心”检索出的信息中有多少比例是用户感兴趣的”,“用户感兴趣的信息中有多少被检索出来了”。“查准率(precision)”与“查全率(recall)”是更为适用于此类需求的性能度量。
ROC与AUC
ROC全称是”受试者工作特征”(Receiver Operating Characteristic)曲线,它源于”二战”中用于敌机检测的雷达信号分析技术,二十世纪六七十年代开始被用于一些心理学、医学检测应用中,此后被引入机器学习领域[Spackman, 1989]。与上节中介绍的P-R曲线相似。我们根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测(正例阈值从100%到0%),每次计算出两个重要量的值,分别以它们为横、纵坐标作图,就得到了”ROC曲线”。与P-R曲线使用查准率、查全率为纵、横轴不同,ROC曲线的纵轴是”真正例率”(True Positive Rate,简称TPR),横轴是”假正例率”(False PositiveRate,简称FPR),基于前面的混淆矩阵中的符号,
样本维度与稀疏
当我们想要寻找区分样本的超平面,理应会想到增加样本的特征维度,但是,在样本量过少时(每增加一个维度就要求样本以指数级增长),极容易造成过拟合,这就是维度灾难。在高维特征空间中, 样本是及其稀疏的,模型也很容易学习到一些噪声,而且维度越高,所需要的样本分布要求也就越高(尽量在每个单元内都有分布),维数灾难造成的另外一个影响是:数据的稀疏性致使数据的分布在空间上不同(实际上,数据在高维空间的中心比在边缘区域具备更大的稀疏性,数据更倾向于分布在空间的边缘区域
不同维数样本空间的形状
俗话说的好,点动成线,线动成面,面动成体,这是对基本三维以及以下维的空间认知,但是根据内接球-维度递推公式,随着维度增大,内接球体体积较小直道没有,也就是,超球体倾向于去中心话,形成各种边角。
监督中的生成与判别
监督学习方法又可以分为生成方法(generative approach)和判别方法(discriminative approach)。所学到的模型分别称为生成模型(generative model)和判别模型(discriminative model)。
- 生成模型
生成的方法就是已知输入变量x和输出标签y,先对他们的联合概率分布建模,然后去计算每一类的条件(后验)概率,按照这个值来完成分类,如将样本分到概率p(y|x)
对上面这种做法的直观解释是:我们已知某一个样本具有某种特征x,现在要确定它输入哪个类,而自然的因果关系是,样本之所以具有这种特征x,是因为它属于某一类。例如,我们要根据体重,脚的尺寸这两个特征x来判断一个人是男性还是女性,我们都知道,男性的体重总体来说比女性大,脚的尺寸也更大,因此从逻辑上来说,是因为一个人是男性,因此才有这种大的体重和脚尺寸。而在分类任务中要做的却相反,是给了你这样个特征的样本,让你反推这人是男性还是女性。
- 判别模型
第二种做法称为判别模型。已知输入变量x,它直接对目标变量y的条件概率p(y|x)建模。即计算样本x属于 每一类的概率。注意,这里和生成模型有一个本质的区别,那就是每一假设x服从何种概率分布,而是直接估计出条件概率p(y|x)。
特点
在监督学习中,生成方法和判别方法各有优缺点,适合于不同条件下的学习问题。
生成方法的特点:
- 生成方法可以还原出联合概率分布P(X, Y),而判别方法则不能
- 生成方法的学习收敛速度更快,即当样本容量增加的时候,学到的模型可以更快地收敛于真实模型
- 当存在隐变量时,仍可以用生成方法学习,此时判别方法就不能用
判别方法的特点:
- 判别方法直接学习的是条件概率P(Y|X)或决策函数f(X),直接面对预测,往往学习的准确率更高;
- 由于直接学习P(Y|X)或f(X),可以对数据进行各种程度上的抽象、定义特征并使用特征,因此可以简化学习问题
机器学习模型分类体系
监督学习
感知机(MLP)/全连接DNN(fc层)
- 感知机分为单层和多层,其本质就是一种全连接网络,全连接网络可以通过有监督去学习特征的输入权重矩阵W,通过隐藏层去模拟学习判断过程(函数),从而实现分类或者回归预测。
- 特点:有很强的非线性拟合能力,理论上可以拟合任何阶的函数,但于此同时,也很难训练以及出现欠拟合过拟合梯度消失或者爆炸等问题
KNN(K近邻算法)
- 一个样本数据集中的k个样本最相似,如果k个样本中大多数属于某一个类别,则该样本也属于这个类别,也就是说,该方法爱确定分类决策上依据近邻的一个或者几个样本决定自己的分类所属类别。其决策时,只与极少量的相邻样本有关。
概率方法
- 贝叶斯(NB):表面上看就条件概率重组了一下,但内涵很深刻,描述了学习这回事~
贝叶斯揭示了概率与似然的奥秘,从公式上看,一个事件发生的后验概率等于其先验乘似然
同时也说明了一个学习道理,任何后验知识的产生都是基于先验的主观理解/初始认知,没有这个基础,那么学习这件事情也并不成立。- 什么是双标,知识局限的产生? 似然是朝着某个固定的方向发展的概率,那么认知也只会朝着那个方向发展。
- 什么又是学习中对于数据的理解,什么时候无法学到新知识? 当把两组数据割裂,看做是独立的分布,那么从贝叶斯公式上看,后验概率将不会相比先验有任何变化。
- Logistic Regression(LR)
首先这个概念就要区别线性回归,逻辑回归中解决的是分类问题,线性搞的是预测。 - 最大熵MEM(与LR同属于对数线性分类模型)
- 贝叶斯(NB):表面上看就条件概率重组了一下,但内涵很深刻,描述了学习这回事~
支持向量机(SVM)
SVM是一种根据支持向量举例寻找最优(最大间隔)分类超平面的方式,举一个例子,当一堆不同重量的红白小球在同一水平面中混杂放置的时候,如何将他们分开,答案是核映射(相当于拍一下桌子让小球飞起来,根据W=-mgh,m不同会导致h的不同,此时飞起来的小球间就有一个可以去们他们类别的超平面)
__凸优化理论:超平面分离定理__:两个凸集合样本最近两点的中垂线为超平面(SVM)决策树(ID3、CART、C4.5)
assembly learning
- Boosting
- Gradient Boosting
- GBDT
- xgboost
- Gradient Boosting
- Bagging
- Random forest
- Stacking
- Boosting
概率图模型
- HMM
这篇讲的真的太好了
本质:隐藏状态+马尔科夫链条
隐马尔可夫模型(hidden Markov model,HMM)是可用于标注问题的统计学习模型,描述由隐藏的马尔可夫链随机生成观测序列的过程,属于生成模型。本章首先介绍隐马尔可夫模型的基本概念,然后分别叙述隐马尔可夫模型的概率计算算法、学习算法以及预测算法。隐马尔可夫模型在语音识别、自然语言处理、生物信息、模式识别等领域有着广泛的应用。
隐马尔科夫模型是生成模型,表示状态序列和观测序列的联和分布,但状态序列是隐藏的,不可观测的。隐马尔科夫模型可以用于标注,这是状态对应着标记。标注问题是给定观测序列预测其对应的标记序列。
- MEMM
- CRF
- HMM
回归预测
非监督
- 聚类
- 基础聚类
- K-mean
- 二分k-mean
- 中值聚类
- 层次聚类
- 密度聚类
- 谱聚类
- 基础聚类
- 主题模型
- 关联分析
- 降维
- 聚类
半监督
强化学习
数理基础
- 概率统计
- 线性代数
- 微积分
机器学习算法总结
wx一图总结
没有最好的分类器,只有最合适的分类器
一点经验之谈:
- 随机森林平均来说最强,但也只在9.9%的数据集上拿到了第一,优点是鲜有短板。
- SVM的平均水平紧随其后,在10.7%的数据集上拿到第一。
- 神经网络(13.2%)和boosting(~9%)表现不错。数据维度越高,随机森林就比AdaBoost强越多,但是整体不及SVM。数据量越大,神经网络就越强。
近邻
典型的例子是KNN,它的思路就是——对于待判断的点,找到离它最近的几个数据点,根据它们的类型决定待判断点的类型。
它的特点是完全跟着数据走,没有数学模型可言。
适用情景:需要一个特别容易解释的模型的时候。比如需要向用户解释原因的推荐算法。
贝叶斯
典型的例子是Naive Bayes,核心思路是根据条件概率计算待判断点的类型。
是相对容易理解的一个模型,至今依然被垃圾邮件过滤器使用。
适用情景:需要一个比较容易解释,而且不同维度之间相关性较小的模型的时候。可以高效处理高维数据,虽然结果可能不尽如人意。
决策树
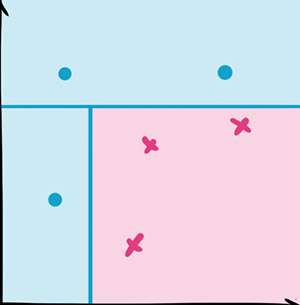
决策树的特点是它总是在沿着特征做切分。随着层层递进,这个划分会越来越细。
虽然生成的树不容易给用户看,但是数据分析的时候,通过观察树的上层结构,能够对分类器的核心思路有一个直观的感受。
举个简单的例子,当我们预测一个孩子的身高的时候,决策树的第一层可能是这个孩子的性别。男生走左边的树进行进一步预测,女生则走右边的树。这就说明性别对身高有很强的影响。
适用情景:因为它能够生成清晰的基于特征(feature)选择不同预测结果的树状结构,数据分析师希望更好的理解手上的数据的时候往往可以使用决策树。
同时它也是相对容易被攻击的分类器。这里的攻击是指人为的改变一些特征,使得分类器判断错误。常见于垃圾邮件躲避检测中。因为决策树最终在底层判断是基于单个条件的,攻击者往往只需要改变很少的特征就可以逃过监测。
受限于它的简单性,决策树更大的用处是作为一些更有用的算法的基石。
随机森林
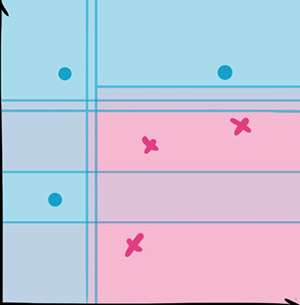
提到决策树就不得不提随机森林。顾名思义,森林就是很多树。
严格来说,随机森林其实算是一种集成算法。它首先随机选取不同的特征(feature)和训练样本(training sample),生成大量的决策树,然后综合这些决策树的结果来进行最终的分类。
随机森林在现实分析中被大量使用,它相对于决策树,在准确性上有了很大的提升,同时一定程度上改善了决策树容易被攻击的特点。
适用情景:
数据维度相对低(几十维),同时对准确性有较高要求时。
因为不需要很多参数调整就可以达到不错的效果,基本上不知道用什么方法的时候都可以先试一下随机森林。
SVM
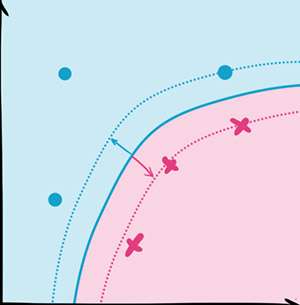
SVM的核心思想就是找到不同类别之间的分界面,使得两类样本尽量落在面的两边,而且离分界面尽量远。
最早的SVM是平面的,局限很大。但是利用核函数(kernel function),我们可以把平面投射(mapping)成曲面,进而大大提高SVM的适用范围。
适用情景:
SVM在很多数据集上都有优秀的表现。
相对来说,SVM尽量保持与样本间距离的性质导致它抗攻击的能力更强。
和随机森林一样,这也是一个拿到数据就可以先尝试一下的算法。
逻辑回归(lr)
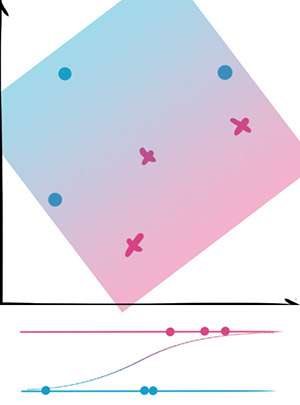
逻辑斯蒂回归这个名字太诡异了,我就叫它LR吧,反正讨论的是分类器,也没有别的方法叫LR。
顾名思义,它其实是回归类方法的一个变体。回归方法的核心就是为函数找到最合适的参数,使得函数的值和样本的值最接近。
例如线性回归(Linear regression)就是对于函数f(x)=ax+b,找到最合适的a,b。LR拟合的就不是线性函数了,它拟合的是一个概率学中的函数,f(x)的值这时候就反映了样本属于这个类的概率。
Boosting
经典算法是Adaboost的实现是一个渐进的过程,从一个最基础的分类器开始,每次寻找一个最能解决当前错误样本的分类器。用加权和的方式把这个新分类器结合到已有的分类器中。
Bagging
随机森林就是Bagging分类器的,他是由弱分类器组合或者随机抽取组成一个强分类器,最终决策基于取normal或者vote出来。这样做的好处就是可以屏蔽掉一些一些子树的错分类结果,极大地提升了决策的鲁棒性和准确性。
Stacking
好像是一种分层集成算法,暂时不管