Natural Language Processing:Key of MMDL
交際に言葉は全て、人達もマシンも
自然语言的本质
以我之浅见,语言既承载了人类认识世界的方式(encoder),也占据了信息交流之间的通道(transform),语言更是能随着文化文明发展而迭代出新的内涵(decoder),更是作为人类这个族群的长期意识存在着,是信息的承载方式与表达形式,信息转化成语音也是具有无限可能性的抽象化过程。人因学习,经历而进步。语言也因时代发展而成长成熟,当人们打破了语言传递信息的壁垒,百分之百传达。我相信,那个互相理解,没有隔阂的世界才会真正到来。
语言与智能
信息熵
衡量信息量的函数,准确的说是信息量的期望值
交叉熵(KL散度)
首先我们定义下KL散度,即Kullback-Leiblev Divergence,描述的是两个分布之间的差别和距离。
语义的进化

词袋模型
词袋模型是一种出现概率计算,它的概率就是,在全部语料库中,这个句子出现的次数,除以所有六个单词组成的句子的次数,即:
$$P\left(x_{1}, x_{2}, \ldots, x_{n}\right)=\frac{c\left(x_{1}, x_{2}, \ldots, x_{n}\right)}{N}$$
N是所有n个词组成的句子(N元组)出现的概率。
这就是一个非常简单的语言模型,就是通过统计次数得到的。
但是这种模型每个单词之间的关系太强了,我们假设每个字的出现概率独立,即:
$$P(\text { I love China })=P(I) P(\text { love }) P(\text { China })$$
如下图所示:
但是这显然是不符合实际的,相邻的两个词之间往往是有关联的,比如I love后面出现you的概率就很大,出现txt的概率就很小。即有一个条件概率的关系,这也是采用词袋模型最具有局限性的地方。
二元语言模型:CR情感分析
词袋模型真的有用吗?
我们用LR模型统计出每个词的正负情感趋势,如下:
$$P(y=1 \mid x)=\frac{1}{1+\exp \left(W^{T} x\right)}$$
向量化:word2vec
word2vec全程叫 word to vector:也就是将词汇转化成对应的向量的一种转化方法
Seq2Seq任务:序列对其任务
eq2Seq是2014年Google提出的一个模型Sequence to Sequence Learning with Neural Networks。论文中提出的 Seq2Seq 模型可简单理解为由三部分组成:Encoder、Decoder 和连接两者的 State Vector (中间状态向量) C 。
在上图many to many的两种模型中,可以看到第四和第五种是有差异的,经典的RNN结构的输入和输出序列必须要是等长,它的应用场景也比较有限。而第四种它可以是输入和输出序列不等长,这种模型便是Seq2Seq模型,即Sequence to Sequence。
Seq2Seq实现了从一个序列到另外一个序列的转换,比如google曾用Seq2Seq模型加attention模型来实现了翻译功能,类似的还可以实现聊天机器人对话模型。经典的RNN模型固定了输入序列和输出序列的大小,而Seq2Seq模型则突破了该限制。
这种结构最重要的地方在于输入序列和输出序列的长度是可变的。
Encoder-Decoder结构
所谓的Sequence2Sequence任务主要是泛指一些Sequence到Sequence的映射问题,Sequence在这里可以理解为一个字符串序列,当我们在给定一个字符串序列后,希望得到与之对应的另一个字符串序列(如 翻译后的、如语义上对应的)时,这个任务就可以称为Sequence2Sequence了。
在现在的深度学习领域当中,通常的做法是将输入的源Sequence编码到一个中间的context当中,这个context是一个特定长度的编码(可以理解为一个向量),然后再通过这个context还原成一个输出的目标Sequence。
如果用人的思维来看,就是我们先看到源Sequence,将其读一遍,然后在我们大脑当中就记住了这个源Sequence,并且存在大脑的某一个位置上,形成我们自己的记忆(对应Context),然后我们再经过思考,将这个大脑里的东西转变成输出,然后写下来。
那么我们大脑读入的过程叫做Encoder,即将输入的东西变成我们自己的记忆,放在大脑当中,而这个记忆可以叫做Context,然后我们再根据这个Context,转化成答案写下来,这个写的过程叫做Decoder。其实就是编码-存储-解码的过程。
而对应的,大脑怎么读入(Encoder怎么工作)有一个特定的方式,怎么记忆(Context)有一种特定的形式,怎么转变成答案(Decoder怎么工作)又有一种特定的工作方式。
好了,现在我们大体了解了一个工作的流程Encoder-Decoder后,我们来介绍一个深度学习当中,最经典的Encoder-Decoder实现方式,即用RNN来实现。
在RNN Encoder-Decoder的工作当中,我们用一个RNN去模拟大脑的读入动作,用一个特定长度的特征向量去模拟我们的记忆,然后再用另外一个RNN去模拟大脑思考得到答案的动作,将三者组织起来利用就成了一个可以实现Sequence2Sequence工作的“模拟大脑”了。 而我们剩下的工作也就是如何正确的利用RNN去实现,以及如何正确且合理的组织这三个部分了。
获取语义向量C最简单的方式就是直接将最后一个输入的隐状态作为语义向量C。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换得到语义变量。
Attention的由来和诞生
原因:Encoder-Decoder结构的局限性
- Encoder和Decoder的唯一联系只有语义编码,即将整个输入序列的信息编码成一个固定大小的状态向量再解码,相当于将信息”有损压缩”。很明显这样做有两个缺点:
- 中间语义向量无法完全表达整个输入序列的信息。
- 随着输入信息长度的增加,由于向量长度固定,先前编码好的信息会被后来的信息覆盖,丢失很多 信息。(不可控的遗忘现象)
- 不同位置的单词的贡献都是一样的
Decoder过程,其输出的产生如下:
$$\begin{aligned}
&y_{1}=g\left(C, h_{0}^{\prime}\right) \
&y_{2}=g\left(C, y_{1}\right) \
&y_{3}=g\left(C, y_{1}, y_{2}\right)
\end{aligned}$$
明显可以发现在生成、、时,语义编码对它们所产生的贡献都是一样的。例如翻译:Cat chase mouse,Encoder-Decoder模型逐字生成:“猫”、“捉”、“老鼠”。在翻译mouse单词时,每一个英语单词对“老鼠”的贡献都是相同的。如果引入了Attention模型,那么mouse对于它的影响应该是最大的。
Attention原理
为了解决中间变量C无法理解整个输入的问题(所以由单连接改为了多连接,还是带权重就是Attention)
Attention模型的特点是Decoder不再将整个输入序列编码为固定长度的中间语义向量 ,而是根据当前生成的新单词计算新的,使得每个时刻输入不同的,这样就解决了单词信息丢失的问题。引入了Attention的Encoder-Decoder模型如下图:
self-attention/transformer
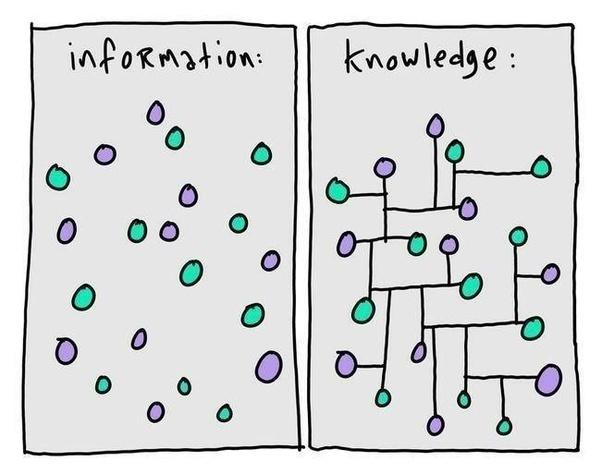
知识图谱
why?
在很长的学习里,我们的人工智能走的还都是统计学还有贝叶斯那一套方法论,基于概率运算以及样本试图“推演”出世界的奥秘,不可否认的是,它确实做到了一些人尚且都还未能做到的事情。
但是那似乎离我们心中的 “人工智能” 还很遥远。我们训练的模型,更像是一个具有统计知识的机器,从关联和概率的角度出发,试图在描述世界背后的 “真理”。
然而,我们更希望的是,像人一样,具有分析和推理能力的机器智能。如果你问我,哪一种形式最接近我心中的 “人工智能”,我会说:知识图谱。
定义
知识图谱,本质上,是一种揭示实体之间关系的语义网络: