
NLU-语音识别
XXXXXXX
简述
输入是由录音组件(麦克风)得到的音频wav文件,然后经过抽样量化编码保存成一个数字信号。即我们经常看到的波形序列(图1的cat的波形)。输出是文字序列,代表这段音频的内容。很显然,按照现在对深度学习任务的划分,这是一个Sequence-to-Sequence的问题。也可以理解为是一个序列标注的问题。该问题与机器翻译,连续手写数字体识别类似,可以划分到一类。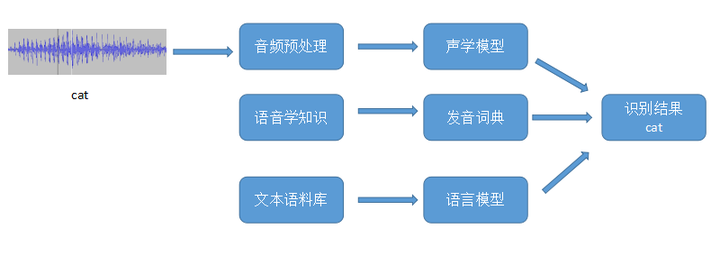
声学模型传统框架
HMM
CTC
LAS
离线端到端的语音识别
CNN/CTC-MEMM
麦克风录制wav
- 降噪算法
- 麦克风阵列Respeaker
语谱特征提取(MFCC:根据人听觉特征设计,越高频人耳越迟钝)
- 分帧(25mm为帧长度),增加滑动窗口(10mm)
- 对帧做短时傅里叶变换FFT转化成该帧声音的频率图
- 幅度谱变换:用颜色颜色表示单帧各频率下的信号强度,组合所有帧得到语谱图
- 两种方向:一种是继续提取特征向量,一种是识别图像
方向一:- 等面积梅尔滤波器滤波(三角滤波)
低频处滤波器密集,门限值大,高频处滤波器稀疏,门限值低。恰好对应了频率越高人耳越迟钝这一客观规律。 - log取对数
- DCT变换(离散余弦变换):得到不同频率下的信号强度,并组合成为该声音信号的特征序列
方向二: - CNN提取语谱图特征并通过CTCloss计算最终的发音类别。
- 等面积梅尔滤波器滤波(三角滤波)
CTC/CNN loss模型(声学模型)
- CNN(VGG16/19模型)+BiRNN(CTCloss)
CTC 解码,在声学模型输出中,往往包含了大量连续并且重复的符号,为此,我们需要将连续重复的符号合并为同一个符号,然后再除去静音分隔标记符,最终得到实际的拼音符号序列。CTC不需要对齐,可以用在输入长度大于输出长度的场合。利用这种方式,可以将CNN提取出的语谱特征与中文拼音进行对齐,从而得到最简化的拼音输出 - 数据集:清华大学 THCHS-30 中文语音数据集、Free ST Chinese Mandarin Corpus 数据集、AISHELL-1开源版数据集、Primewords Chinese Corpus Set 1 数据集、aidatatang_200zh 数据集、MagicData 数据集。其中训练语音 625 000句,验证集语音2000句。
- CNN(VGG16/19模型)+BiRNN(CTCloss)
MEMM模型(HMM语言模型)
- 从声学模型中获得发音后,就需要对发音进行解码,采用HMM对声音进行联合解码得到最终的文字输出。
MEMM 在限定条件下求解最优条件概率,在训练过程中使特征多项式 fi(x,y)收敛于 λi,并求解此时的 xi与 yi-1 的正则化因子,在此解码过程中直接求得条件概率p(yi|yi-1,xi),词错误率19.18%
- 从声学模型中获得发音后,就需要对发音进行解码,采用HMM对声音进行联合解码得到最终的文字输出。
创新点:结合离线十分高效的特征提取以及具有极高特征提取效果的CNN网络对语谱进行识别。满足离线场景下的对话需求,同时也达到了想要的准确率。
后续的优化方向
- RNN-T:全称是Recurrent Neural Network Transducer,是在CTC的基础上改进的,CTC的缺点是它没有考虑输出之间的dependency,而RNN-T则在CTC模型的Encoder基础上,又加入了将之前的输出作为输入的一个RNN,称为Prediction Network,再将其输出的隐藏向量与encoder得到的j结果放到一个joint network中,得到输出logit再将其传到softmax layer得到对应的class的概率。RNN-T能够联合优化声学模型与语言模型,由于RNN-T是针对每帧输入特征进行预测输出,即不用等语音全部说完再出结果,因此可以更好的应用在流式识别上,尤其是在嵌入式设备。
- Transformer:可以通过借助RNN-T在语音识别上的优势,利用tranformer替换RNN-T中的RNN结构,实现并行化运算,加快训练过程。
Sq2Sq 直接端到端翻译方法
这种方式很方便,甚至可以夸语言直接进行语音翻译,但是需要的数据量和算力也很大